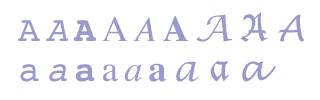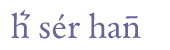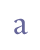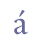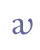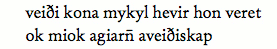| Menota main page List of contents |
 |
|
|
Chapter 2. Basic units: characters and words2.1 Introduction Version 2.0 (16 May 2008). Links updated 12 July 2016. 2.1 IntroductionWhen transcribing a text, the transcriber will usually make a distinction between the individual characters, the white space between some of the characters, the words made up by sequences of characters, and the punctuation marks which are inserted between some of the words. The actual encoding can be as straightforward as the example in ch. 1 above, in which characters, punctuation marks and spaces have been typed directly from the keyboard: Reiðr var þá Vingþórr er hann vaknaði ok síns hamars um saknaði, skegg nam at hrista, skör nam at dýja, réð Jarðar burr um at þreifask. In a more complex encoding, the transcriber might like to identify the basic units as such, so that a distinction easily can be drawn between single characters, words, punctuation marks and the white space surrounding them. This chapter will discuss these basic units and how they can be encoded specifically, if needed, using elements like <c> for individual characters and <w> for individual words. 2.2 CharactersThe basic unit in any transcription of an alphabetic script is the individual letters. In a linguistic context a distinction is often drawn between the abstract entity of a grapheme and the representation of graphs in a written document. Variant forms are referred to as allographs, e.g. the Roman type of s and the Fraktur (black letter) type. The terminology is analogous to the distinction between phonemes, phones and allophones. For a general introduction to this terminology, see Sture Allén 1971 or, more recently, Manfred Kohrt 1985. In this handbook we shall adopt the terminology of the Unicode Standard. The fundamental distinction drawn is between characters and glyphs. Characters are, as Unicode defines it, “the smallest components of written language that have semantic value”, while glyphs are “the shapes that characters can have when they are rendered or displayed” (cf. Unicode 4.0, ch. 2.2). What the transcriber sees in the source document is a series of individual glyphs, and the act of transcribing essentially involves connecting these glyphs to the characters at the transcriber's disposal. The concept of a character is similar to, but not identical with the linguistic concept of a grapheme. These concepts are notoriously difficult, but for the purposes of this handbook we believe that the Unicode usage is robust and sufficiently well-defined. The Unicode Standard puts great emphasis on the fact that individual characters may be represented by a number of glyphs, and is therefore reticent to accept as new characters what it percieves to be variant glyphs. It will be obvious to most people that the various shapes of letters in printed type faces, such as Baskerville, Palatino, Helvetica etc., should not be seen as different characters, as shown in fig. 2.1.
Fig. 2.1. Various shapes (glyphs) of the characters “A” and “a” in Courier, Times and Lucida typefaces Unicode draws a distinction between small (minuscule) characters such as “a” and large (majuscule) characters such as “A”, since there is a possible semantic value attached to each set of characters. Thus, “the white house” can refer to any house which is white in colour, while “the White House” refers (normally) to one specific building. It can be argued that the same applies to the distinction between Roman types, “a”, and italics, “a”. For example, while “Metope” refers a poem by the Norwegian author Olaf Bull, Metope (according to a widespread bibliographical practice) refers to the book in which this poem is published (a book which, co-incidentally, bears the same name as one of the poems contained in the book). However, Unicode does not regard italics (or bold type) as individual characters. There are good reasons for this, but the example serves to illustrate the fact that the definition of a character is not always clear-cut. Medieval Nordic manuscripts were written in the Latin alphabet from the very beginning. The basic inventory is thus the characters a-z / A-Z. They were supplemented with a number of new (or borrowed) characters, several ligatures and a variety of diacritical marks. There was also a large number of abbreviation marks in use, especially in Old Icelandic and Old Norwegian manuscripts. We shall go through the inventory of ordinary characters, i.e. those based on the set a-z / A-Z, in ch. 5 and abbreviation marks in ch. 6, and we shall refer to both types as characters. In fact, some abbreviation marks behave as ordinary characters in the sense that they occupy a separate position on the base line. On the other hand, many components of ordinary characters are diacritical, i.e. placed above (or through or below) another character, and thus akin to typical abbreviation marks. This means that the rules for transcribing ordinary characters and abbreviation marks should be identical. We believe that it is possible to identify a base line in all texts, as shown in fig. 2.2. We recommend that the transcriber identifies each separate character on the base line and record this in the same sequence as in the manuscript. Thus, the characters in fig. 2.2 would be transcribed as “abpþ” or “abpþ”. Note that the last character may be encoded with its Unicode code point, “þ” at 00FE, or with an entity, “þ”. Both encodings are strictly equivalent. Entities are explained in ch. 1.5 and discussed further in ch. 5.2.
Fig. 2.2. Position of characters on the base line If there are marks of any sort placed above, through or below any base line character, we recommend that these marks (if they are to be interpreted as characters) are transcribed immediately after the base line character. In general, we refer to these marks as diacriticals. As mentioned above, abbreviation marks are also frequently written above (and in some cases through or below) a base-line character. Assuming that the sign above “h” should be referred to with the entity “&er;”, the transcription of the very first word in fig. 2.3 would be “h&er;”.
Fig. 2.3. Diacritical marks and abbreviation marks Diacritical marks are often seen as forming an integral part of a base line character and the whole encoded as a single character. This applies to accent marks, such as the one above “e” in fig. 2.3. This combination of a base line character and a combining mark can be encoded as a single character, in Unicode referred to as LATIN SMALL LETTER E WITH ACUTE and the hexidecimal code value 00E9. As we shall see below, it is possible to decompose this letter in Unicode and refer to it as a combination of LATIN SMALL LETTER E and COMBINING ACUTE ACCENT. We would like to emphasize that both encodings are strictly equivalent. Abbreviation marks, on the other hand, are usually treated as separate characters and encoded as characters in their own right. From a purely graphical point of view, the distinction between the acute accent in “é” and abbreviation marks such as the “zigzag” mark and the bar, both exemplified in fig. 2.3, is far from obvious, but the semantics are different. The acute accent may in some manuscripts be used to signify length, but it is often used quite freely, sometimes only to distinguish one minim character from another. Abbreviation marks have a definite (if sometimes ambiguous) meaning and can be expanded into one or more characters; the zigzag mark above “h” in fig. 2.3 signifies “er”, and the bar above “n” signifies another “n”. 2.2.1 Rules for encoding charactersWe suggest the following basic rules for encoding characters, irrespective of whether they are ordinary (alphabetic) characters or abbreviation marks. 1. Each character is encoded according to its position in the direction of writing. 2. Alphabetical characters on the base line are encoded first: 2.1 If the character belongs to the ordinary Latin character set a-z / A-Z (commonly known as ISO 646 or Basic Latin) it is always encoded as such. 3. Abbreviation marks occupying a separate position on the base line are encoded in the same manner as alphabetical characters. This applies to e.g. LATIN SMALL LETTER P WITH STROKE THROUGH DESCENDER (for “per” or “par”), as explained in ch. 6 below. 4. Alphabetical characters with diacritical marks, e.g. “é”, are encoded in one of two equivalent ways: 4.1 As a base line character + one or more combining marks. Thus the character “é” would be encoded as “e” + “&combacute;” (the latter entity meaning COMBINING ACUTE ACCENT). 5. Characters with abbreviation marks are encoded in the same manner as alphabetical characters, i.e. in one of two equivalent ways: 5.1 As a base line character + one or more combining marks. Thus the first character in fig. 3.2 above would be encoded as “h” + “&er;” (the latter entity meaning COMBINING ABBREVIATION MARK “ER”). As a rule, we would recommend the first solution, since the number of combinations of base line characters and combining abbreviation marks is very high. Cf. the discussion in ch. 6.4. 6. If there is more than one combining character, they are encoded in this order: (a) Combinations with the base line character within the x height of the base line character. 7. If there is more than one combining character in any of the three positions defined in (6) above, they are encoded in a clockwise direction, beginning at 6 o'clock and moving through 9 o'clock, 12 o'clock etc. 2.2.2 Entities and Unicode valuesBy using entities it is possible to define as many characters as one believes are necessary for the transcription of a certain corpus of texts. However, since most applications now fully support Unicode, we recommend that characters in the Unicode Standard are encoded by their Unicode code points. Note that the type of encoding is specifed at the very begining of an XML file. If the specification is <?xml version="1.0" encoding="ISO-8859-1"?> entities must be used for all characters outside Basic Latin and Latin-1 Supplement. Thus, “a”, “é” and “þ” can be entered directly, but characters like “ǫ” (LATIN SMALL LETTER O WITH OGONEK) must be encoded with an entity, “&oogon;”. If, however, the encoding is specified as <?xml version="1.0" encoding="UTF-8"?> all characters in the Unicode Standard can be encoded with their Unicode code points, without resorting to entities. In TEI P5, all entities must be declared in a separate list. A complete list of entities for Medieval Nordic texts is part of the Menota schema, and can be consulted in Appendix D.1. An encoding using these entities will always be valid with respect to character encoding (but may, of course, be invalid for other reasons). In the Menota schema, entities are linked to code points defined in the MUFI character recommendation, so that if a Menota text is displayed with a fully compliant MUFI font, all entities will be displayed correctly. If an encoder, for some reason, would like to encode a character which is not in the Menota list of entities, this character has to be declared in the header of the file, or by exchanging the Menota list of entities with an extended list. The Basic Multilingual Plane of the Unicode Standard has 65,536 different code points. This includes a large Private Use Area (PUA), comprising some 6,000 code points. This area can be used for characters not defined in the Standard (so far). Our present recommendation is to use this area for characters not included in the Unicode Standard and to coordinate the allocation of codepoints with the recommendations by the Medieval Unicode Font Initiative. It should be noted that the use of PUA is an interim solution. A long-term solution is obviously to apply to Unicode for the inclusion of additional characters and/or use other rendering techniques (such as OpenType). Code points in Unicode are usually given in hexadecimal format, in which each digit spans a sequence of 16 positions, 0-1-2-3-4-5-6-7-8-9-A-B-C-D-E-F. Thus, 0001 equals 1 in the decimal system, 000F equals 15, 0010 equals 16 etc. The whole range thus goes from 0000 to FFFF (65,535). The PUA is located at E000-F8FF. The Latin alphabet is the first to be described in the Unicode Standard. As was mentioned, many characters in Unicode can be defined in several ways, either as a single, composite character or as combination of a base line character and one or more combining marks. (a) Commonly used characters have a single description in Unicode. This applies to all base line characters in the Latin alphabet.
(b) Composite characters may be described in more than one way. Thus “a with acute accent” can be encoded as a combination of “a” and a combining acute accent or as a single character, “a with acute accent”. Both descriptions are equivalent:
(c) Some characters are not found in Unicode and must therefore be allocated to the Private Use Area (PUA), either as a character with its own code point or as a combination of an existing character and a combining diacritical mark in the PUA. The ligature “av” is not included in the Unicode Standard (as of v. 5.0), and since we would rather not encode it as a sequence of “a” + “zero width joiner” + “v”, we have allocated it to a code point in the PUA, EF97.
Encoding with entities referring to the PUA may look unnecessarily complicated. It should be borne in mind, however, that the great majority of characters are defined in Unicode, and in many transcriptions the need for special characters in the PUA will not arise. With appropriate fonts, the transcriber does not need to spend much time on technicalities of this kind. Finally, it should be noted that a text may be encoded with a mixture of Unicode code points and entities even for characters within the Unicode Standard. For the sake of clarity, some encoders might like to insert combining marks as entities. Thus, the example above might be encoded as: h&er; sér han&bar; even if both COMBINING ZIGZAG ABOVE and COMBINING OVERLINE are part of the Unicode Standard, at 035B and 0305 respectively. Some XML editors may not show combining characters in correct positions, so that it may be more legible to use entities for these characters, “&er;” for the combining zigzag above and “&bar;” for the combining bar above. 2.2.3 Encoding characters as suchIn some cases, a character should be encoded as a character and not as a part of a word, e.g. in a grammatical discussion. The TEI P5 Guidelines recommend the element <c> for this type of encoding.
A sentence like the following, from Einar Haugen's edition of the First Grammatical Treatise, X, hann er samsettr i latinu af c ok s. can be encoded as <c>X</c>, hann er samsettr i latinu af <c>c</c> og <c>s</c>. When displaying this text, the contents of the <c> element can be put in italics: X, hann er samsettr í látinu af c ok s. The <c> element should be restricted to contexts in which characters are cited as characters. The encoding of initials and littera notabilior is discussed in ch. 4.8 below. 2.3 Words2.3.1 Basic mark-upThis chapter will introduce some important elements and attributes for the encoding of word or word parts, mostly based on ch. 17.1 “Linguistic Segment Categories” in the TEI P5 Guidelines.
As a rule, medieval Nordic manuscripts in the Latin alphabet are written with a clearly identifiable space between each word. This obviously facilitates the work for the transcriber, since the word is a basic linguistic unit in grammars and dictionaries. In a simple transcription, word division can simply be entered by the space bar on the keyboard. Thus, a piece of text (from Barlaams ok Josaphats saga ch. 48) might be transcribed as En ef ver fallum i hinar fornno syndir oc huerfum aptr til hinna fyrrv misverka sem hundr til spyu sinnar þa kann lettlega at vera at oss kunni til hannda at berazt sem i guðspialleno segir. Here, each word is delimited by a space (or a punctuation mark). However, for a more detailed analysis it can be convenient to identify each word with a separate <w> element (for “word”). The <w> element functions as a container for information on levels of text representation (cf. ch. 3 below) and morphological analysis (cf. ch. 8). In this example, each word has been identified by the <w> element, and the lemma (dictionary entry) specified as an attribute to the <w> element: <w lemma="en">En</w> <w lemma="ef">ef</w> <w lemma="vér">ver</w> <w lemma="falla">fallum</w> <w lemma="í">i</w> <w lemma="hinn">hinar</w> <w lemma="forn">fornno</w> <w lemma="synd">syndir</w> etc. For practical reasons, each word has a separate line in this encoding. Unless otherwise specified, it is assumed that there is white space between each <w> element. Ch. 3 will discuss further levels of transcription (facsimile and normalised), and ch. 8 how words can be marked for morphological categories. 2.3.2 Deviations in word division (words written together or apart)Although words as a rule are separated by spaces in medieval Nordic manuscripts, there are many exceptions to this rule. For this reason, a distinction should be drawn between graphical words and lexical words. A graphical word is a sequence set out by space on either side, while a lexical word is a member of the set of word forms defined by grammars and dictionaries for the language in question. In the great majority of cases, graphical and lexical words are identical. However, we sometimes see that a preposition and its object may be written as a single word (“aveiðiskap” = “á veiðiskap”), or that compounds are written as two separate words (“veiði kona” = “veiðikona”).
Fig. 2.4. Text adopted from Barlaams saga ok Josaphats, Holm perg. fol. nr. 6, f. 138 If the transcriber wishes to analyse two (or more) graphical words as a single lexical word, we suggest that this is done by putting the whole sequence within the <w> element: <w>veiði kona</w> Information on e.g. lemma can be given as an attribute to the <w> element: <w lemma="veiðikona">veiði kona</w> The sequence “veiði kona” thus appears within a single element. In other words, the transcriber interprets it as one lexical word, “veiðikona”. The space is left untouched, so that in a display of the transcription, the sequence will still show up as two graphical words, “veiði” and “kona”. However, since both graphical words are placed within a single element the lemma will refer to both parts. The converse case is a single graphical word which the transcriber would like to analyse as two (or more) lexical words, e.g. “aveiðiskap” = “á veiðiskap”. Each lexical word should be placed within a <w> element, and information on lemma, morphological form etc. can be given within each <w> element. However, to generate a correct display of the text, i.e. a display with no space between each part, we suggest that the <seg> element is used with a type attribute. The value “nb” would indicate that there is no break between the parts in the <w> element. If the lemma is given by way of an attribute, the encoding would look like this: <seg type="nb"> <w lemma="á">a</w> <w lemma="veiðiskap">veiðiskap</w> </seg> In some rather marginal cases, a sequence may be encoded as both types. A simplified example from Codex Regius is “aravk stola” which should be read as “a ravkstola”. This sequence might be encoded in this way: <seg type="nb"> <w lemma="á">a</w> <w lemma="r&oogon;kstóll">ravk stola</w> </seg> This encoding shows that “a” in “aravk stola” is a lexical word, sc. the preposition “á”, and that “ravk stola” is another lexical word, sc. the noun “rökstóll” (for practical reasons, “ö” is used here rather than “o ogonek”). It will also allow a correct display of the sequence, since it specifies that there should be no space between “a” and “rauk stola”, and the space between “rauk” and “stola” is also encoded (analoguous to the encoding of “veiði kona” above). Enclitic words may be encoded in a smiliar way, e.g. “emk” which should be read as “em” + “(e)k”, “am I”: <seg type="enc"> <w lemma="vera">em</w> <w lemma="ek">k</w> </seg> 2.3.3 Encoding of word constituentsThe encoder might want to encode constituent parts of a word, e.g. prefixes, roots, derivational forms etc. We recommend using the <m> element (for “morpheme”) in such cases (cf. ch. 17.1 in the TEI P5 Guidelines). This element may also be used for constituent parts such as “veiði” and “kona” in the examples above. The <m> element may contain information on level of text representation, lemma etc. We shall repeat the encoding of “veiði kona” above: <w lemma="veiðikona">veiði kona</w> Now, if the encoder wishes to add lexicographical (or other) information to the two constituent parts, that can easily be done by inserting <m> elements in the <w> element: <w lemma="veiðikona">veiði kona <m baseForm="veiði">veiði</m> <m baseForm="kona">kona</m> </w> This encoding would make a clear distinction between lemmata on the first level of encoding, in this case “veiðikona”, and the base form, @baseForm, of each constituent part, in this case “veiði” and “kona”. Lemmatisation is further discussed in ch. 8 below and is here only given as an example of a word-based type of mark-up. Grammatical information can also be conveniently attached to the word through the @msa (morphosyntactical analysis) attribute. This is also discussed in ch. 8. 2.4 Punctuation and white spaceHaving introduced elements for the encoding of individual characters and words, it can also be useful to tag punctuation marks specifically. The TEI P5 Guidelines do not have any punctuation element, so this has been added in the Menota namespace, <me:punct>. Note the prefix “me:” which indicates that the element belongs to the Menota namespace and is not part of the elements defined in TEI P5. See ch. 1.9 above on the use of namespaces in TEI schemes. Remember that namespaces are allowed with RELAX NG schemas, but not with a DTD (as in TEI P4). In the latter case, the prefix “me:” should simply be dropped.
The three levels of text representation, facs, dipl and norm, will be explained in ch. 3 below. Suffice it here to say that at the facsimile level, the manuscript is recorded in great detail, on the diplomatic level, it is somewhat normalised, and on the normalised level it is fully regularised according to standard grammars and dictionaries. 2.4.1 PunctuationIn ch. 2.3.1 above, we said that a text can be encoded character by character. Punctuation marks are simply inserted where they occur in the manuscript, even if the position is wrong according to modern rules. If the actual punctuation in Barlaams ok Jospahats saga is added, the example above looks like this: En ef ver fallum i hinar fornno syndir. oc huerfum aptr. til hinna fyrrv misverka sem hundr til spyu sinnar. þa kann lettlega at vera. at oss kunni til hannda at berazt. sem i guðspialleno segir. In addition to punctuation marks like FULL STOP, COMMA, COLON, SEMICOLON and HYPHEN, there are a number of specific medieval punctuation marks, including an early form of the QUESTION MARK and a PUNCTUS ELEVATUS. A full list of additional punctuation marks can be found in the MUFI character recommendation with appropriate character entities. For example, the PUNCTUS ELEVATUS, which sometimes appear in Medieval Nordic texts, should be encoded with the entity “&punctelev;”. If a text is encoded using the <w> element, we recommend using a <me:punct> element for punctuation marks: <w>En</w> <w>ef</w> <w>ver</w> <w>fallum</w> <w>i</w> <w>hinar</w> <w>fornno</w> <w>syndir</w> <me:punct>.</me:punct> <w>oc</w> <w>huerfum</w> <w>aptr</w> <me:punct>.</me:punct> etc. The main reason for doing so will become clear in ch. 3, in which several levels of transcription is discussed. At a diplomatic level, the transcriber should encode the punctuation marks exactly where they are in the source, but at a normalised level, some punctuation marks should be suppressed, some should be retained and some should be added. For a full discussion, please see ch. 4.8. 2.4.2 White spaceIn a single-level transcription, spaces are simply inserted by the space bar. Note that in XML as well as in HTML any amount of white space (spaces, tabs and line breaks) are interpreted as a single space. It is not possible to encode a long space in the mansucript simply by hitting the space bar several times. Any distinctions in space length must be encoded specifically. In our experience, there is no significant variation in word spacing in Medieval Nordic manuscripts. If, however, a transcriber believes there are more than one length of the space, the simplest way of encoding this is probably to define the standard space, code point 0020, as the default space and to define deviating spaces with reference to the list of various space lenghts in the Unicode chart General Punctuation, 2000-200B. For recommended entities, see the MUFI character recommendation. As for the interpretation and display of spaces in a multi-level transcription, we suggest the following three rules: 1. A transcription using the <w> and the <me:punct> element should be displayed with a space immediately after each element. The example in ch. 2.4.1 above would then be interpreted (e.g. by an XSLT style sheet) as En ef ver fallum i hinar fornno syndir . oc huerfum aptr . This is correct in so far as there should be a space after each punctuation mark, but wrong in so far as there should not be a spece before the punctuation mark. The following additions to the general rule must be made with respect to the <me:punct> element: 2. When displaying the text, there should not be any white space before a <me:punct> element. The example above will then be correctly displayed as En ef ver fallum i hinar fornno syndir. oc huerfum aptr. That is also true for any sequence of punctuation characters, e.g. Hann segir," Ek veit eigi." In this example, no space is displayed before the comma nor before the final sequence of a full stop and a closing quotation mark. However, the position of the space in connection with the opening quotation mark is wrong. For this specific punctuation mark, the space should be before, not after: Hann segir, "Ek veit eigi." This will be taken care of by the XSLT style sheet, which treats opening quotation marks as an exception to rule (2). Another exception are Roman numerals, which typically are delimited by a dot immediately before and after the number: Hann er .xij. vetra gamall. We recommend that the delimiters are encoded as part of the number, and thus contained in the <num> element: <w>Hann</w> <w>er</w> <num>.xij.</num> <w>vetra</w> <w>gamall</w> <me:punct>.</me:punct> Similarly, if numbers are encoded as words, delimiters should be contained in the <w> element: <w>Hann</w> <w>er</w> <w>.xij.</w> <w>vetra</w> <w>gamall</w> <me:punct>.</me:punct> However, if an ordinary punctuation mark is positioned immediately before a word rather than after the preceding word, we recommend that a @rend attribute is used with the value “rightlocation”. Thus, Hann kemr .opt. should be encoded as <w>Hann</w> <w>kemr</w> <me:punct rend="rightlocation">.</me:punct> <w>opt</w> <me:punct>.</me:punct> The XSLT style sheet will then be instructed to position the first punctuation mark accordingly, i.e. immediately in front of the following word. Finally, the following addition to the general rule must be made with respect to the <w> element: 3. If two or more <w> elements are contained in a <seg> element (type="nb"), in the display on the <facs> and <dipl> levels there should not be any space after the <w> elements except for the last <w> element contained in the <seg> element. Thus, the following sequence should be displayed as “alande” on the <me:facs> and the <me:dipl> level, with no word division, but as “á landi” on the <me:norm> level, with word division. In the latter case, rule (1) applies, which states that a space should be displayed after each <w> element. In the former case, rule (3) entails that there should not be displayed any space after the first of the two words in the <seg> element. Also see ch. 2.3.2 above. If the above-mentioned rules 1-3 are added to the XSLT style sheet, texts should be displayed correctly. See Appendix F.2 for an example of how this can be implemented. |
First published 8 December 2005. Last updated 12 July 2016. Webmaster. |