Chapter 9. Scribal and editorial intervention
Version 3.1 (30 December 2025) – cf. version 3.0 (12 December 2019)
by Odd Einar Haugen
9.1 Introduction
This chapter covers the encoding of changes to the manuscript text made by the scribe and similar changes made during the modern transcription of the manuscript. Ch. 9.2 deals with additions, deletions, transpositions and substitutions made by the scribe or later users of the manuscript. Ch. 9.3 treats insertions, suppressions and corrections made by the transcriber, annotator or editor during the transcription of the manuscript text. While it can be useful to make a distinction between the roles of scribe, compiler, annotator or corrector for the first type of changes, we will in general refer to these roles as that of the scribe (or, metonymically, as that of a hand). Similarly, even if a distinction may be drawn between the modern roles of transcriber, annotator and editor, we will refer to these roles as that of the editor. Finally, ch. 9.4 deals with comments of any kind, i.e. text that comes in addition to the manuscript text.
9.2 Scribal intervention
In the manuscript text and in the margins of the manuscript, we often encounter different kinds of corrections that we would like to encode. These changes can be divided into four different groups depending on the nature of the change and its relevance for the reading of the manuscript text or our knowledge about the manuscript: (1) additions, (2) deletions, (3) transpositions and (4) corrections.
9.2.1 Additions by the scribe
This section only deals with additions made by a scribal hand. Text inserted by a modern editor is dealt with in ch. 9.3.1 below.
The element <add> should be used for any additions made in the manuscript, whether it was done by the scribe himself or a later compiler, annotator or corrector. Scribal additions are traditionally referred to as being “with younger hand” or the like. It may be desirable to make a distinction between the contemporaneous hand in the manuscript and any later hand, but it is not always a simple task to do so. However, the act of addition is usually easy to spot, as it is typically found above the line or in the margin. For this reason, we recommend that the type and place of the addition should be specified, but not necessarily the hand responsible for the addition
We suggest that there are two different types of scribal additions, and that the encoding should reflect this distinction.
(1) Supplying of text is the addition of any piece of text which the scribe thought was missing, often not more than a few characters or words. The obvious position of such additions was immediately above the line, but they can also be found in the margin of the manuscript.
(2) Glossing of text is the addition of translated items of the text, often a single word. Glosses, too, are typically found above the line.
| Elements & attributes | Obl/Opt | Contents |
|---|---|---|
| <add> | Contains characters, words or phrases added to the manuscript text or in the margins of the manuscript by the scribe, an annotator or a corrector. Attributes include: | |
| @type | Optional | Indicates the type of addition made. If it is a scribal supplying of text, the value would be ‘supplement’, if it is a scribal gloss, the value would be ‘gloss’. |
| @place | Optional | Indicates where the addition is made. Suggested values include ‘inline’, ‘supralinear’, ‘infralinear’ and ‘margin’. |
| @hand | Optional | Signifies the scribe who made the addition. Sample values may be ‘scribe’, ‘mainscribe’ and ‘laterscribe’. |
Changes in scribal hands are not considered additions. For markup of such phenomena, the <handShift/> element should be used (cf. ch. 3.14 above). Note that this element is parallel to empty elements like <pb/>, <cb/> and <lb/> in that it only points to a break in the text.
9.2.1.1 Encoding of text supplied by the scribe

Ill. 9.1. Words added above the line. Äldre Västgötalagen. Holm B 59, f. 6v, l. 8–11.
In the second line of ill. 9.1, there are no less than three supralinear words. The first is var ‘was’, which is inserted between Iak and þa a þingi. The encoding in a single-level transcription would be as follows:
. . .
<w><me:dipl>Iak</me:dipl></w>
<add place="supralinear">
<w><me:dipl>var</me:dipl></w>
</add>
<w><me:dipl>þa</me:dipl></w>
<w><me:dipl>a</me:dipl></w>
<w><me:dipl>þingi</me:dipl></w>
. . .

Ill. 9.2. A word added in the margin. The Old Norwegian Homily Book. AM 619 4to, f. 13v, l. 8–10.
In the second line of ill. 9.2, the word “of” is placed in the margin, indicated by a triangular insertion sign. In a multi-level encoding, we recommend that additions are encoded on the facsimile and diplomatic level, but not on the normalised level. This is an example of a word added in the margin:
. . .
<w>
<choice>
<me:facs>hældr</me:facs>
<me:dipl>hældr</me:dipl>
<me:norm>heldr</me:norm>
</choice>
</w>
<w>
<choice>
<me:facs>rænr</me:facs>
<me:dipl>rænr</me:dipl>
<me:norm>rennr</me:norm>
</choice>
</w>
<w>
<choice>
<me:facs>hugren</me:facs>
<me:dipl>hugren</me:dipl>
<me:norm>hugrinn</me:norm>
</choice>
</w>
<w>
<choice>
<me:facs>tom&rdes;</me:facs>
<me:dipl>tomr</me:dipl>
<me:norm>tómr</me:norm>
</choice>
</w>
<w>
<choice>
<me:facs><add place="margin">of</add></me:facs>
<me:dipl><add place="margin">of</add></me:dipl>
<me:norm>of</me:norm>
</choice>
</w>
<w>
<choice>
<me:facs>um</me:facs>
<me:dipl>um</me:dipl>
<me:norm>um</me:norm>
</choice>
</w>
<w>
<choice>
<me:facs>alla</me:facs>
<me:dipl>alla</me:dipl>
<me:norm>alla</me:norm>
</choice>
</w>
<w>
<choice>
<me:facs>luti</me:facs>
<me:dipl>luti</me:dipl>
<me:norm>hluti</me:norm>
</choice>
</w>
. . .The location of the addition is indicated by the attribute @place. In this example, the addition is made outside the text column and therefore described by the value ‘margin’. Note that we are not encoding the triangular signs as such.
Scribal additions are often brief, perhaps consisting of only one or a few characters above the line or likewise in the margin. In some cases, however, the addition can be longer, especially when placed in the margin. These additions should as far as possible be located within the main text.
As discussed in ch. 6.5.2 above, when a scribe adds parts of a word above the line, in order to complement the word, e.g. “v. ” for fimti (type c) or for reasons of space, e.g. “eᷤ” for es (type d), we do not regard this as an addition as long as it seems to be part of the actual writing process. These instances will be encoded with appropriate supralinear entities, such as &ssup; for the supralinear “s” in eᷤ for es. The element <add> is thus reserved for any additions which are made (or most likely were made) after the first writing session, either by the scribe himself or by a later hand.
9.2.1.2 Encoding of glosses by the scribe
A special kind of scribal intervention is the addition of glosses, typically above the line. In Old Norse manuscripts, Latin words or phrases in the text may be translated into Old Norse and placed as glosses above the line. Sometimes, it is the other way: an Old Norse word on the line is glossed, i.e. explained, by a Latin word above the line. We suggest that the gloss is encoded by the <add> element with the @type attribute having the value ‘gloss’.
In the Icelandic homily book, Holm perg 15 4to, fol. 1r.9, the word “stirðleikstónn” has been glossed as “immitis” above the line. We suggest the following encoding (simplified):
<w>
<me:facs>ſtirþléicſtǫ́ɴ</me:facs>
<me:dipl>stirþléikstǫ́nn</me:dipl>
<me:norm>stirðleikstónn</me:norm>
</w>
<w>
<me:facs><add type="gloss">i<am>&bar;</am>mitis</add></me:facs>
<me:dipl><add type="gloss">i<ex>m</ex>mitis</add></me:dipl>
<me:norm><add type="gloss">immitis</add></me:norm>
</w>9.2.1.3 Display of scribal additions
In the stylesheet for the Menota archive, scribal additions are displayed by insertion signs, either downwards-pointing (for additions inline, above or below the line in the manuscript) or upwards-pointing (for additions in the margin of the manuscript). As for glosses, we suggest using top left and top right half brackets. To the best of our knowledge, there is no commonly accepted way of indicating glosses in edited texts.
| Element and attributes | Display |
|---|---|
| <add place="inline"> <add place="supralinear"> <add place="infralinear"> | Downwards-pointing insertion signs, e.g. Iak ⸌var⸍ þa a þingi ok ⸌var⸍ mæn siax |
| <add place="margin"> | Upwards-pointing insertion signs, e.g. hældr rænr hugren tomr ⸝of⸜ um alla luti |
| <add type="gloss"> | Half upper brackets, e.g. Septimus heitir stirðleikstónn ⸢immitis⸣, því at i hvers manns lífláti er nauð ok ótti |
In the Unicode Standard, the first set of insertion signs, ⸌...⸍, are located at 2E0C and 2E0D, the second set, ⸝...⸜, at 2E1D and 2E1C.
We suggest that it is sufficient to display two main types, so that additions within the text column (typically supralinear, but also inline and infralinear) are displayed by the first set and additions in the margin with the second set. It can be left to the photographic facsimile to show exactly how the additions have been placed.
The third set of insertion signs, ⸢...⸣, are located at 2E22 and 2E23 in the Unicode Standard. We suggest that a gloss is encoded directly after the glossed word on the line.
Other stylesheets may display additions with other types of signs, by a note rather than by signs, or not at all.
9.2.2 Deletions by the scribe
This section only deals with deletions made by a scribal hand. Text suppressed by a modern editor is dealt with in ch. 9.3.2 below.
9.2.2.1 Encoding of scribal deletions
The element <del> should be used for deletions made in the manuscript by the scribe himself or a later compiler, annotator or corrector. Identifying a deletion in a manuscript is usually simple, while identifying the hand responsible for the deletion can be difficult. For this reason, we suggest that the first identification should be obligatory, the second optional.
| Elements & attributes | Obl/Opt | Contents |
|---|---|---|
| <del> | Contains a character, word or passage deleted or otherwise indicated as superfluous or spurious in the manuscript text by a scribe, annotator or corrector. Attributes include: | |
| @rend | Obligatory | This attribute is used to classify the deletion, using any convenient typology. Sample values include ‘overstrike’, ‘erasure’ and ‘subpunction’. |
| @hand | Optional | Signifies the scribe who made the deletion. Values include ‘scribe’, ‘mainscribe’ and ‘laterscribe’. |

Ill. 9.3. Characters deleted by erasure. Konungs skuggsjá. AM 243 bα fol, f. 5ra, l. 24–26.
In the middle line of ill. 9.3, two characters have been erased in the word skilningar laus. In a single-level encoding, the deletion will be recorded as it appears in the manuscript:
. . .
<w><me:dipl>þviat</me:dipl></w>
<w><me:dipl>skilningar <del rend="erasure">sk</del>laus</me:dipl></w>
<w><me:dipl>skepna</me:dipl></w>
. . .In a multi-level encoding, we recommend that deletions are encoded on the facsimile and diplomatic level, but not on the normalised level. This is the same recommendation as for the <add> element discussed above:
. . .
<w>
<choice>
<me:facs>þviat</me:facs>
<me:dipl>þviat</me:dipl>
<me:norm>því at</me:norm>
</choice>
</w>
<w>
<choice>
<me:facs>ſkilningar <del rend="erasure">ſk</del>lauſ</me:facs>
<me:dipl>skilningar <del rend="erasure">sk</del>laus</me:dipl>
<me:norm>skilningarlaus</me:norm>
</choice>
</w>
<w>
<choice>
<me:facs>skepna</me:facs>
<me:dipl>skepna</me:dipl>
<me:norm>skepna</me:norm>
</choice>
</w>
. . .Text which has been encoded as deleted must be at least partly legible in the manuscript. If the deleted text is completely illegible we recommend that the deleted passage should be encoded with the <gap/> element, described in ch. 8.2 above.
Sometimes, a scribe would delete a word and add another above the line. We regard this as a substitution which should be encoded with a combination of a <del> and an <add> element. See ch. 9.2.4 below.
9.2.2.2 Display of deletions by the scribe
In the stylesheet for the Menota archive, scribal deletions are displayed by vertical bars with quills. The beginning of the deletion will be indicated by a vertical bar with the quill to the right, and the end of the deletion with a vertical bar with a quill to the left.
| Element | Display |
|---|---|
| <del> | Vertical bars with quills, e.g. þviat ſkilningar ⸠ſk⸡laus ſkepna |
In the Unicode Standard, the vertical bar with the quill to the right is located at 2E20, and the vertical bar with a quill to the left at 2E21.
As mentioned above, scribes had various ways of making deletions, such as overstrike, erasure and subpunction. If these have been encoded by the @rend attribute it is tempting (and not particularly difficult) to render them in a similar way in the display. However, we recommend using a single pair of signs for deletions, and leave it to the photographic facsimile to show exactly how the deletion has been done.
Other stylesheets may display deletions by other types of signs, by a note rather than by signs, or not at all.
9.2.3 Transpositions by the scribe
The sequence of words in a manuscript was sometimes transposed by the scribe or by a later hand, using various types of transposition signs. In the encoding, we would like to be able to include both the original order and the transposed order.

Ill. 9.4. Transpositions of two words. The Old Norwegian Homily Book. AM 619 4to, fol. 47r, l. 8–10.
In ill. 9.4, there are two transposition signs, one above each of the two words “vaner” and “váro” (simplified spelling) in the middle line indicating that the sequence should rather be “váro vaner”. There are different types of transposition signs; this one looks like three dots in a downwards-pointing triangle.
9.2.3.1 Encoding of scribal transpositions
There are two pairs of elements used in this handbook, <orig> + <reg> and <sic> + <corr>. The first pair should be used for correction made by the scribe such as transpositions. Corrections by the editor should be enocded by the <sic> + <corr> elements, as exemplified in ch. 9.3.3 below.
| Elements & attributes | Obl/Opt | Contents |
|---|---|---|
| <orig> | Contains the reading in the manuscript. Attributes include: | |
| @rend | Obligatory | The correction markers in the manuscript. A typical value would be ‘transposition-signs’. |
| <reg> | Contains the reading corrected in the manuscript. Attributes include: | |
| @type | Obligatory | The type of correction. We recommend the value ‘transposition’. |
| @resp | Optional | The one who is responsible for the regularisation. Sample values include ‘scribe’, ‘mainscribe’ and ‘laterscribe’. |
In a single-level encoding, we recommend that the original reading is given within the <orig> element with a @rend attribute specifying the type of transposition signs in the manuscript. The transposed reading is encoded in an ensuing <reg> element, and both elements are contained in a <choice> element. The <reg> element should have a @type attribute with the value ‘transposition’, and preferably a @resp attribute with a suitable value, e.g. ‘mainscribe’ or ‘laterscribe’, or, if a distinction is difficult to draw, just ‘scribe’:
. . .
<choice>
<orig rend="transposition-signs">
<w><me:dipl>vaner</me:dipl></w>
<w><me:dipl>vꜵ́ro</me:dipl></w>
</orig>
<reg type="transposition" resp="mainscribe">
<w><me:dipl>vꜵ́ro</me:dipl></w>
<w><me:dipl>vaner</me:dipl></w>
</reg>
</choice>
. . .In a multi-level encoding, one or more words will be added within the <orig> as well as within the <reg> element:
. . .
<choice>
<orig rend="transposition-signs">
<w>
<choice>
<me:facs>ꝩaner</me:facs>
<me:dipl>vaner</me:dipl>
<me:norm>vanir</me:norm>
</choice>
</w>
<w>
<choice>
<me:facs>ꝩꜵ́ꝛo</me:facs>
<me:dipl>vꜵ́ro</me:dipl>
<me:norm>váru</me:norm>
</choice>
</w>
</orig>
<reg type="transposition" resp="mainscribe">
<w>
<choice>
<me:facs>ꝩꜵ́ꝛo</me:facs>
<me:dipl>vꜵ́ro</me:dipl>
<me:norm>váru</me:norm>
</choice>
</w>
<w>
<choice>
<me:facs>ꝩaner</me:facs>
<me:dipl>vaner</me:dipl>
<me:norm>vanir</me:norm>
</choice>
</w>
</reg>
</choice>
. . .If the text is annotated for morphology (or syntax), we recommend that only the words in the <orig> element get linguistically annotated, so as to avoid duplication of the annotation. This is a similar case to that of any text being added by the editor in the <supplied> element. Supplied text should also be exempted from annotation.
9.2.3.2 Display of scribal transpositions
In the stylesheet for the Menota archive, the display is different in single-level and multi-level transcriptions. In a multi-level transcription, the <orig> reading is displayed on the facsimile level and the <reg> reading on the diplomatic and normalised levels. In a single-level transcription, priority is given to the <reg> reading, since this is the one presumably intended by the scribe. The stylesheet therefore displays the <reg> reading, while the <orig> reading is displayed in a note.
| Elements | Display in a single-level transcription | Display in a multi-level transcription |
|---|---|---|
| <orig> | Displayed in a note to the whole <orig> sequence. | Displayed in the running text on the <me:facs> level with no indication of a transposition. |
| <reg> | Displayed in the running text. | Displayed in the running text on the <me:dipl> and <me:norm> levels, highlighted in green. |
In a multi-level transcription, the stylesheet for the Menota archive uses green colour on the diplomatic and normalised levels to indicate that a passage is the result of a transposition.
Other stylesheets may display transpositions differently. It is, for example, not obvious that the reading of the <reg> element should be given priority over the <orig> element, since the transposition at least in some cases may be made by a later scribe and thus not compliant with the scribe’s intentions.
9.2.4 Substitutions by the scribe
This section describes the markup of text substituted by a scribe, i.e. where a scribe deletes text and replaces it with some other text. These actions should be encoded by a combination of the <del> and <add> elements introduced in ch. 9.2.1 and ch. 9.2.2 above. It is not always possible, however, to ascertain the relation between the two. If someone has deleted the originally written text inline this does not automatically mean that a corresponding addition above the line or in the margin is made by the same scribe. A correspondence can be expressed by the @resp attribute, whenever the editor is able make this identification.
A common type of substitution occurs when a scribe makes changes to one character in order to make it into another one, e.g. making an“e” into an “o”.

Ill. 9.5. Substitution of one character with another. The Old Norwegian Homily Book. AM 619 4to, f. 26v, l. 7–11.
In the 4th line of ill. 9.5, the 5th word has been changed from “ſundum” to “ſẏndum”. We suggest that this action is encoded as a deletion of the “u” and the addition of the “y”. The change consists of adding a stem to the “u” and presumably a dot above it.
We recommend that in a single-level encoding, the <del> and <add> elements are included on the same level, one after another. This is what the above substitution would look like in a transcription on the diplomatic level:
. . .
<w>
<me:dipl>s<del hand="mainscribe">u</del>
<add hand="mainscribe" place="inline">y</add>ndu<ex>m</ex></me:dipl>
</w>
. . .In a multi-level encoding, we recommend that the <del> and <add> elements are included at the facsimile and diplomatic level, while the normalised level should give the text as it was intended:
. . .
<w>
<choice>
<me:facs>ſ<del hand="mainscribe">u</del>
<add hand="mainscribe" place="inline">ẏ</add>ndu<am>&bar;</am></me:facs>
<me:dipl>s<del hand="mainscribe">u</del>
<add hand="mainscribe" place="inline">y</add>ndu<ex>m</ex></me:dipl>
<me:norm>syndum</me:norm>
</choice>
</w>
. . .

Ill. 9.6. Substitution of one character with another written above. Landslǫg Magnúss Hákonarsonar. Holm perg 34 4to, f. 8r, l. 17–19.
Another common example is the substitution by writing the replacement above (or below) the word. In ill. 9.6, in the middle of the middle line, the word “yður” has been altered, most likely by the scribe, so that the original “u” has been deleted by subpunctuation and an “e” has been added as the replacement character above the line. This word should be marked up as follows in a single-level encoding on the diplomatic level:
. . .
<w>
<me:dipl>yð<del hand="mainscribe" rend="subpunction">u</del>
<add hand="mainscribe" place="supralinear">e</add>r</me:dipl>
</w>
. . .As stated above, we recommend that in a multi-level encoding, the <del> and <add> elements are included at the facsimile and diplomatic level, while the normalised level has the text as it was intended:
. . .
<w>
<choice>
<me:facs>yð<del hand="mainscribe" rend="subpunction">u</del>
<add hand="mainscribe" place="supralinear">e</add>r</me:facs>
<me:dipl>yð<del hand="mainscribe" rend="subpunction">u</del>
<add hand="mainscribe" place="supralinear">e</add>r</me:dipl>
<me:norm>yðr</me:norm>
</choice>
</w>
. . .In this example, the corrected form “yðer” is rendered as “yðr” in normalised orthography. See the discussion on orthography in ch. 9.3.4 below.
If a substitution spans a structural boundary, we refer to the advice in ch. 16.2 below.
9.2.4.1 Display of scribal substitutions
In the stylesheet for the Menota archive, the display is different in single-level and multi-level transcriptions. In a multi-level transcription, the <del> reading is displayed on the facsimile level and the <add> reading on the diplomatic and normalised levels. In a single-level transcription, priority is given to the <add> reading, since this is the one presumably intended by the scribe. The stylesheet therefore displays the <add> reading, while the <del> reading is displayed in a note.
| Elements | Display in a single-level transcription | Display in a multi-level transcription |
|---|---|---|
| <del> | Displayed with deletion signs, as described in ch. 9.2.1.2 above. | Displayed in the running text on the <me:facs> level with no indication of a substitution. |
| <add> | Displayed with addition signs, as described in ch. 9.2.2.2 above. | Displayed in the running text on the <me:dipl> and <me:norm> levels, highlighted in green. |
In a multi-level transcription, the stylesheet for the Menota archive uses the green colour on the diplomatic and normalised levels to indicate that a passage is the result of a substitution.
Other stylesheets may display substitutions differently. It is, for example, not obvious that no indication should be given on the facsimile level, especially if the substitution is thought to be part of the immediate writing process by the scribe.
9.3 Editorial intervention
When transcribing medieval material we sometimes encounter text which for one reason or another should be supplied, suppressed or corrected. It may be obvious cases, such as physical damage to the manuscript which calls for restoration, but it may also be passages which look fine in the manuscript but come across as erroneous. In the following, we shall discuss three types of editorial intervention: (1) insertions, (2) suppressions and (3) corrections.
9.3.1 Insertions by the editor
If text seems to be missing in the manuscript, the editor can supply it using the <supplied> element. We suggest that there are two major types of supplied text:
(1) Restoration is the supplying of any piece of text which obviously is missing, typically a few characters or words. It may be an initial that the scribe did not fill in or a physical damage to the manuscript which has left some of the text missing. Restoration will in general be specified by the @reason attribute and the value ‘restoration’. Even if the restoration of the text may seem more or less certain, we recommend that the person who is responsible for the restoration is identified in a @resp attribute. We regard restoration as the default type of supplied text.
(2) Emendation is the supplying of any piece of text, typically one or a few words that give a more sensible or complete reading from a grammatical or semantic point of view. An emendation will be specified by the @reason attribute and the value ‘emendation’. Also here, the person who is responsible for the emendation should be identified in a @resp attribute.
| Elements & attributes | Obl/Opt | Contents |
|---|---|---|
| <supplied> | Signifies text supplied by the editor in order to restore or emend the manuscript text. Attributes include: | |
| @reason | Obligatory | Indicates why the text has been supplied. It should be given one of the two values, ‘restoration’ or ‘emendation’. The former covers text which is lost through damage or left empty by intention, text which is unclear, and text which is simply illegible. The latter covers editorial enhancement with respect to grammar, lexicon, syntax, context or the like. |
| @resp | Obligatory | Indicates the individual responsible for the addition of characters, words or passages contained within the <supplied> element. |
| @source | Optional | States the source of the supplied text if this can be located. |
9.3.1.1 Encoding of restorations
Restoration is a common feature in the transcription of manuscripts. The various types discussed in ch. 8 belong to this category, including lost text, such as in lacunas (ch. 8.2), empty spaces (ch. 8.3), and unclear passages (ch. 8.4).

Ill. 9.7. Missing initial. Gregory’s Homilies and Dialogues. AM 677 4to, f. 1v, l. 1–3.
In ill. 9.7, an initial is obviously missing in the first line. It can hardly be any doubt that the intended character is the ‘S’ of the normalised word sá ‘this’. This is a single-level encoding on the diplomatic level:
. . .
<w><me:dipl><supplied reason="restoration" resp="encoder">
<c type="initial">S</c></supplied>a</me:dipl></w>
<w><me:dipl>eiɴ</me:dipl></w>
<w><me:dipl><ex>madr</ex></me:dipl></w>
. . .In a multi-level encoding, the facsimile level should encode the text as is, using the <space/> element to record any significant space in the manuscript. The supplied reading will be given on the normalised level, while the diplomatic level may opt for either the <space/> or the <supplied> encoding, as discussed in ch. 8.3.1 above. Here, the supplied reading is given on both the diplomatic and normalised levels:
. . .
<w>
<choice>
<me:facs><space quantity="1" unit="chars"/>a</me:facs>
<me:dipl><supplied reason="restoration" resp="encoder">
<c type="initial">S</c></supplied>a</me:dipl>
<me:norm><supplied reason="restoration" resp="encoder">
<c type="initial">S</c></supplied>á</me:norm>
</choice>
</w>
<w>
<choice>
<me:facs>eıɴ</me:facs>
<me:dipl>eiɴ</me:dipl>
<me:norm>einn</me:norm>
</choice>
</w>
<w>
<choice>
<me:facs><am>ᛉ</am></me:facs>
<me:dipl><ex>madr</ex></me:dipl>
<me:norm>maðr</me:norm>
</choice>
</w>
. . .A similar example is found in ch. 8.3 above, from the law text AM 309 fol.

Ill. 9.8. Damage to the parchment caused by acidity. The Old Norwegian Homily Book. AM 619 4to, f. 9v, l. 23–30.
For a slightly more extensive restoration, we may return to the example in ch. 8.2 above. This is a single-level encoding on a diplomatic level, where “GI1931” refers to Gustav Indrebø’s 1931 edition of The Old Norwegian Homily Book:
. . .
<w><me:dipl>Fegiarn</me:dipl></w>
<w><me:dipl><ex>maðr</ex></me:dipl></w>
<w><me:dipl>er</me:dipl></w>
<w><me:dipl>lícr</me:dipl></w>
<w><me:dipl>hælviti</me:dipl></w>
<w><me:dipl>þvi</me:dipl></w>
<w><me:dipl>er</me:dipl></w>
<w><me:dipl>aldrigin</me:dipl></w>
<w><me:dipl><supplied reason="restoration" resp="GI1931">fyl</supplied>lisc</me:dipl></w>
<pc><me:dipl>.</me:dipl></pc>
. . .In a multi-level encoding, the <gap/> element will be used on the facsimile level, while the <supplied> element offers a restoration on the normalised level and optionally on the diplomatic levels. Also here, the gap has been supplied on the diplomatic level in addition to the normalised level:
. . .
<w>
<choice>
<me:facs>þ&vins;i</me:facs>
<me:dipl>þvi</me:dipl>
<me:norm>því</me:norm>
</choice>
</w>
<w>
<choice>
<me:facs>er</me:facs>
<me:dipl>er</me:dipl>
<me:norm>er</me:norm>
</choice>
</w>
<w>
<choice>
<me:facs>aldrigin</me:facs>
<me:dipl>aldrigin</me:dipl>
<me:norm>aldrigin</me:norm>
</choice>
</w>
<w>
<choice>
<me:facs><gap reason="damage" agent="acidity" quantity="3" unit="chars"/>lisc</me:facs>
<me:dipl><supplied reason="restoration" resp="GI1931">fyl</supplied>lisc</me:dipl>
<me:norm><supplied reason="restoration" resp="GI1931">fyl</supplied>lisk</me:norm>
</choice>
</w>
<pc>
<choice>
<me:facs>.</me:facs>
<me:dipl>.</me:dipl>
<me:norm>.</me:norm>
</choice>
</pc>
. . .

Ill. 9.9. An illegible word. Niðrstigningar saga. AM 645 4to, f. 51v, l. 32–35.
In ill. 9.9, the first character in the second line is so smudged that it has become illegible. As stated in ch. 8.4.1 above, we recommended that illegible characters are encoded by a standard sign such as 25CC DOTTED CIRCLE. A single-level encoding of this passage is given in ch. 8.4.1, while we here offer a multi-level encoding with supplied text on the diplomatic as well as the normalised level:
<pb ed="ms" n="51v"/>
. . .
<lb ed="ms" n="32"/>. . .
<w>
<choice>
<me:facs><unclear reason="smudged">◌</unclear></me:facs>
<me:dipl><supplied reason="restoration" resp="OEH">ok</supplied></me:dipl>
<me:norm><supplied reason="restoration" resp="OEH">ok</supplied></me:norm>
</choice>
</w>
<w>
<choice>
<me:facs>ml<am>&bar;</am>a</me:facs>
<me:dipl>m<ex>æ</ex>la</me:dipl>
<me:norm>mǽla</me:norm>
</choice>
</w>
<w>
<choice>
<me:facs>s<am>&asup;</am></me:facs>
<me:dipl>s<ex>va</ex></me:dipl>
<me:norm>svá</me:norm>
</choice>
</w>
<pc>
<choice>
<me:facs>.</me:facs>
<me:dipl>.</me:dipl>
<me:norm>.</me:norm>
</choice>
</pc>
. . .Note that the reading on the facsimile level uses the dotted circle for the illegible character, while the diplomatic and normalised levels offer a restoration in the <supplied> element.
9.3.1.2 Encoding of emendations
Emendation is here used to describe the addition of one or more characters or words intended to make the text simpler or smoother according to criteria of morphology, syntax or semantics. There is a traditional and long-standing distinction between emendations based on other manuscripts (or foreign exemplars) of the work, ope codicum, and emendations based on the subjective judgment of the editor, ope ingenii. In the following, we shall give examples of both.
The first example is of an emendation ope codicum. The bottom line in ill. 9.10 reads “Vittra er hyggiændi guðlegra luta sva sem gefet er manne”. This looks fine, and if the Latin exemplar for this part of the homily book, Alcuin’s De virtutibus et vitiis, had not been available, nobody might have proposed an emendation.

Ill. 9.10. Supplied text. The Old Norwegian Homily Book. AM 619 4to, f. 14r, l. 26–30.
However, based on Alcuin’s version “Prudentia est rerum divinarum humanarumque, prout homini datum est, scientia”, Gustav Indrebø added “ok mannlegra” to the Old Norwegian text in his 1931 edition. This seems like a convincing rendering of “humanarumque”, and as such it is an emendation ope codicum. If Indrebø’s emendation is accepted, this would be a single-level encoding:
. . .
<w><me:dipl>guðleg<ex>ra</ex></me:dipl></w>
<w><me:dipl>luta</me:dipl></w>
<supplied reason="emendation" resp="GI1931" source="Alcuin-text">
<w><me:dipl>ok</me:dipl></w>
<w><me:dipl>mannlegra</me:dipl></w>
</supplied>
. . .In a multi-level encoding, the facsimile level will be left empty for the supplied words, for the very reason that they are not in the manuscript. As discussed several times above, the normalised level should offer the supplied words, while it is optional for the diplomatic level to do so. In the following example, both of the latter levels include the supplied text:
. . .
<w>
<choice>
<me:facs>guðleg<am>&asup;</am></me:facs>
<me:dipl>guðleg<ex>ra</ex></me:dipl>
<me:norm>guðligra</me:norm>
</choice>
</w>
<w>
<choice>
<me:facs>luta</me:facs>
<me:dipl>luta</me:dipl>
<me:norm>hluta</me:norm>
</choice>
</w>
<supplied reason="emendation" resp="GI1931" source="Alcuin-text">
<w>
<choice>
<me:facs></me:facs>
<me:dipl>ok</me:dipl>
<me:norm>ok</me:norm>
</choice>
</w>
<w>
<choice>
<me:facs></me:facs>
<me:dipl>mannlegra</me:dipl>
<me:norm>mannligra</me:norm>
</choice>
</w>
</supplied>
. . .The second example is of an emendation ope ingenii. This is offered by ill. 9.11, in which the middle line reads “Iesus Christus, sá er nú er krossfestr, hafi þangat sent”. Depending on the understanding of the rules for object deletion in Old Norse, it might make sense to add þik, “Iesus Christus, sá er nú er krossfestr, hafi þik þangat sent”. The editor’s ingenium is in this case based on the syntactic analysis of Old Norse.

Ill. 9.11. Supplied text. Niðrstigningar saga. AM 645 4to, f. 55v, l. 5–7.
As suggested above, the <supplied> element should be specified with the attribute @reason and the value ‘emendation’. This would be a single-level encoding of the last four words:
. . .
<w><me:dipl>hafe</me:dipl></w>
<w><me:dipl><supplied reason="emendation"
resp="OEH">þik</supplied></me:dipl></w>
<w><me:dipl>þaɴgat</me:dipl></w>
<w><me:dipl>seɴt</me:dipl></w>
. . .In a multi-level encoding, the facsimile level will simply be empty for the supplied word, while we also here have given it on the diplomatic and normalised level:
. . .
<w>
<choice>
<me:facs>hafe</me:facs>
<me:dipl>hafe</me:dipl>
<me:norm>hafi</me:norm>
</choice>
</w>
<w>
<choice>
<me:facs></me:facs>
<me:dipl><supplied reason="emendation" resp="OEH">þik</supplied></me:dipl>
<me:norm><supplied reason="emendation" resp="OEH">þik</supplied></me:norm>
</choice>
</w>
<w>
<choice>
<me:facs>þaɴgat</me:facs>
<me:dipl>þaɴgat</me:dipl>
<me:norm>þangat</me:norm>
</choice>
</w>
<w>
<choice>
<me:facs>ſeɴt</me:facs>
<me:dipl>seɴt</me:dipl>
<me:norm>sent</me:norm>
</choice>
</w>
. . .In general, emendations belongs on the normalised level and will not be part of the encoding on the facsimile level. The diplomatic level is a border case, but also at this level, emendations are offered in the case of obvious errors on part of the scribe. Many of the Menota texts are only encoded on the diplomatic level, and in order for them to be ready for syntactic annotation, it is advisable to emend the texts also on this level.
9.3.1.3 Display of editorial insertions
In the stylesheet for the Menota archive, supplied text as a default is displayed in square brackets, in line with the Leiden convention (see e.g. Dow 1969), p. 5, and the EpiDoc Guidelines. If, however, the <supplied> element has the @reason attribute and the ‘emendation’ value, the stylesheet uses open angle brackets for the display (cf. Dow 1969, p. 11).
| Element and attributes | Display |
|---|---|
| <supplied
reason="restoration"> | Square brackets, 005B and 005D respectively, e.g.
[S]á einn maðr |
| <supplied reason="emendation"> | Open angle brackets, 27E8 and 27E9, e.g.
hafi ⟨þik⟩ þangat sent
|
Other stylesheets will display supplied text differently. In particular, they may display supplied text with the same signs whatever the reason for supplying the text, not making any distinction between what has been termed restoration and emendation here.
9.3.2 Suppression by the editor
If a piece of text is thought to be superfluous, the editor might want to indicate the superfluous passage and in effect suppress it. This is common editorial practice, although it should always be done in a way that records the suppressed passage (whether by suppression signs or by a note stating the manuscript reading).
Dittographies are probably the most common cause for suppression. The TEI P5 Guidelines, ch. 11.3.1.7, recommends the <surplus> element for dittographies, and we do the same. This element can also be used to suppress passages which the editor believe are superfluous for other reasons, such as being excessive or even incoherent. As with the <supplied> element, this is more often than not a subjective evaluation by the editor, based on his or her understanding of the rules of grammar.
As for other instances of editorial suppression, we recommend using the <sic> and <corr> elements, so that the <sic> element contains the suppressed reading and the <corr> element is left empty. This will be dealt with in ch. 9.3.3 below.
Note. Earlier versions of the Menota Handbook introduced the <me:expunged> element (later renamed as <me:suppressed>) for editorial suppression. For backwards compatibility, these elements are still part of the Menota schemas. We recommend, however, that the standard <surplus> element or the <sic> and <corr> elements are being used for editorial suppression.
9.3.2.1 Encoding of suppressed text
| Elements & attributes | Obl/Opt | Contents |
|---|---|---|
| <surplus> | Contains text which the editor believes should be recognised as superfluous. | |
| @reason | Optional | Indicates the reason for the piece of text being superfluous. It can be given values like ‘dittography’, ‘excess’ and ‘incoherence’. |
In the following, we give examples of <surplus> text due to dittography, ill. 9.12, and incoherence, ill. 9.13.

Ill. 9.12. Dittography. Konungs skuggsjá. AM 243 ba fol, f. 2v, col. B, l. 18–21.
In ill. 9.12, there is a dittography “sialfr sialfr” at the end of the first line and in the opening of the second. It has not been deleted by the scribe, so it is left to the editor to suppress it. This is what it would look like in a multi-level encoding:
. . .
<w>
<choice>
<me:facs>ꝩaʀ</me:facs>
<me:dipl>vaʀ</me:dipl>
<me:norm>várr</me:norm>
</choice>
</w>
<w>
<choice>
<me:facs>ſialꝼr</me:facs>
<me:dipl>sialfr</me:dipl>
<me:norm>sjalfr</me:norm>
</choice>
</w>
<lb ed="ms" n="19"/>
<surplus reason="dittography">
<w>
<choice>
<me:facs>ſialꝼr</me:facs>
<me:dipl></me:dipl>
<me:norm></me:norm>
</choice>
</w>
</surplus>
<w>
<choice>
<me:facs>oc</me:facs>
<me:dipl>oc</me:dipl>
<me:norm>ok</me:norm>
</choice>
</w>
. . .From a pragmatic point of view, the second, not the first, instance of “sialfr” has been defined as a dittography. Both instances will be displayed on the facsimile level, but only the first “sialfr” will be displayed on the diplomatic and normalised levels. For this reason, these levels are empty in the example above.


Ill. 9.13. Incoherence. Henrik Harpestreng. NKS 66 8vo, f. 73r, l. 9–13 and f. 73v, l. 1–2.
In ill. 9.13, the conjunction “oc” (the last word on f. 73r) does not really make any sense. The text has been corrected by the editor, following the edition by Christian Molbech (1826). In the following single-level encoding on the diplomatic level, the word “oc” has been encoded with the <surplus> element and the ‘incoherence’ value of the @reason attribute:
. . .
<lb ed="ms" n="11"/>
<w><me:dipl>oc</me:dipl></w>
<w><me:dipl>thæt</me:dipl></w>
<w><me:dipl>dughær</me:dipl></w>
<w><me:dipl>for</me:dipl></w>
<w><me:dipl>spolorm</me:dipl></w>
<w><me:dipl>of</me:dipl></w>
<w><me:dipl>m<lb ed="ms" n="12"/>an</me:dipl></w>
<w><me:dipl>drikær</me:dipl></w>
<w><me:dipl>thæt</me:dipl></w>
<w><me:dipl>ællær</me:dipl></w>
<w><me:dipl>of</me:dipl></w>
<w><me:dipl>m<lb ed="ms" n="13"/>an</me:dipl></w>
<w><me:dipl>smørs</me:dipl></w>
<w><me:dipl>mæth</me:dipl></w>
<surplus reason="incoherence">
<w><me:dipl>oc</me:dipl></w>
</surplus>
<pb ed="ms" n="73v"/>
<lb ed="ms" n="1"/>
<w><me:dipl>hænnæ</me:dipl></w>
. . .In short, the <surplus> element will be used whenever there is a piece of text that in its entirety can be regarded as superfluous, and thus should be suppressed. Other cases of suppression will be dealt with below.
9.3.2.2 Display of editorial suppression
In the stylesheet for the Menota archive, text suppressed by the editor is displayed in curly brackets. Deletions by the scribe, on the other hand, is displayed in vertical bars with quills, as shown in ch. 9.2.2.2 above.
| Element | Display |
|---|---|
| <surplus> | Curly brackets, 005B and 005D respectively, e.g. vaʀ sialfr {sialfr} |
Note that if a word has been deleted on a specific level in a multi-level encoding, such as the second “sjalfr” in ill. 9.12 above, the stylesheet should not display any deletion signs on this level. This is to preclude a display such as “... várr sjalfr {} ok ...”, where the more intuitive display would be “... várr sjalfr ok ...”, suppressing the second “sialfr” silently.
If the reason for the suppression is a dittography, as exemplified here, some printed editions will use the signs 2E21 and 2E20. Since these are identical to the signs recommended for deletions by the scribe, only in the reverse order, we do not recommend this usage.
Other stylesheets will display suppressed text differently, for example by overstrike.
9.3.3 Corrections by the editor
When transcribing a text, corrections of obvious mistakes in the manuscript text can be encoded with the elements <sic> and <corr>, grouped within a <choice> element.
| Elements & attributes | Obl/Opt | Contents |
|---|---|---|
| <sic> | Contains text reproduced although apparently incorrect or inaccurate. | |
| <corr> | Contains the correct form of a passage apparently erroneous in the manuscript text. | |
| @resp | Obligatory | Indicates the individual responsible for the correction of characters, words or passages contained within the <corr> element. |

Ill. 9.14. Correction by editor. The Old Norwegian Homily Book. AM 619 4to, f. 8v, l. 23–26.
In the third line of ill. 9.14, the editor has decided to correct “tíu æggiat” ‘with ten edges’ to “tuí æggiat” ‘with two edges, i.e. double-edged’. This is an example of a minim correction from iu to ui. In a single-level transcription, the encoding is straight-forward. Note, however, that the <sic> and <corr> elements must be placed within a <choice> element:
. . .
<w><me:dipl>hvasser</me:dipl></w>
<w><me:dipl>sem</me:dipl></w>
<w>
<me:dipl>
<choice>
<sic>tíu æggiat</sic>
<corr resp="Indrebo1931">tuí æggiat</corr>
</choice>
</me:dipl>
</w>
<w><me:dipl>sværð</me:dipl></w>
. . .In a multi-level transcription, we suggest that the <sic> element is located at the facsimile level, while the <corr> element is located at the diplomatic and normalised level:
. . .
<w>
<choice>
<me:facs>hvaſſer</me:facs>
<me:dipl>hvasser</me:dipl>
<me:norm>hvassir</me:norm>
</choice>
</w>
<w>
<choice>
<me:facs>ſem</me:facs>
<me:dipl>sem</me:dipl>
<me:norm>sem</me:norm>
</choice>
</w>
<w>
<choice>
<me:facs><sic>tíu æggiat</sic></me:facs>
<me:dipl><corr resp="Indrebo1931">tuí æggiat</corr></me:dipl>
<me:norm><corr resp="Indrebo1931">tvíeggjat</corr></me:norm>
</choice>
</w>
<w>
<choice>
<me:facs>ſværð</me:facs>
<me:dipl>sværð</me:dipl>
<me:norm>sverð</me:norm>
</choice>
</w>
. . .Editors will emend the text to varying degrees. In his edition of The Old Norwegian Homily Book in AM 619 4to, Gustav Indrebø (1931) corrected the text in a number of cases. In the Menota archive, his corrections have been given priority, so that the manuscript readings in the <sic> element have been moved into notes.
9.3.3.1 Display of editorial corrections
In the stylesheet for the Menota archive, the display is different in single-level and multi-level transcriptions. In a multi-level transcription, the <sic> reading is displayed on the facsimile level and the <corr> reading on the diplomatic and normalised levels. In a single-level transcription, priority is given to the <corr> reading, since this is the one suggested by the editor. The stylesheet therefore displays the <corr> reading, while the <sic> reading is displayed in a note.
| Elements | Display in a single-level transcription | Display in a multi-level transcription |
|---|---|---|
| <sic> | Displayed in a note to the whole <sic> sequence. | Displayed in the running text on the <me:facs> level with no indication of a correction. |
| <corr> | Displayed in the running text. | Displayed in the running text on the <me:dipl> and <me:norm> levels., highlighted in green. |
In a multi-level transcription, the stylesheet for the Menota archive uses green colour on the diplomatic and normalised levels to indicate that a passage is the result of a correction.
Other stylesheets may display corrections differently. It is, for example, not obvious that no indication should be given on the facsimile level, especially if the correction is thought to be helpful for the readers of the text.
9.3.4 Orthography of supplied and corrected text
When the encoder would like to supply or correct text using the <supplied> or <reg> elements, the orthography will depend on the level of transcription.
On the normalised level, one should simply follow the regularised orthography for the language in question. For Old Icelandic and Old Norwegian we recommend in general the orthography of the Old Norse Dictionary in Copenhagen. However, as discussed in ch. 10 below, there may be other normalised orthographies, for example appropriate to late medieval texts.
On the diplomatic level, the orthography should follow the manuscript in question. Whenever the transcriber is in doubt, it is advisable to select the most transparent and readable form. For example, in the encoding of the bottom line of ill. 9.11 in ch. 9.3.1.2 above, one might suggest that the supplied word “mannlegra” should have been rendered as “mannlegra” in analogy with “guðlegra”, or, perhaps, as “mannlegra”, assuming that a double “nn” would have been written with a single “n” with a bar above. In our view, this level of reconstruction is too detailed and not really helpful. We recommend simply “mannlegra”.
Another example is the supplied text in the space left by the scribe in AM 309 fol, exemplified in ill. 8.3 in ch. 8.3.1 above. Even if the scribe only left room for approximately three characters, we recommend a fully supplied reading such as “halfa mork” rather than e.g. “.ɟ. ᴍ.” on the diplomatic and normalised levels. A supplied reading like “.ɟ. ᴍ.” might however be appropriate for the facsimile level.
With respect to the orthography of the diplomatic level, it would be reasonable to use the spelling “mork” in accordance with the manuscript, while a normalised spelling would be “halfa mǫrk”. This is what a multi-level encoding would look like for the phrase in question:
<pb ed="ms" n="42v"/>
. . .
<lb ed="ms" n="18"/>
. . .
<w>
<choice>
<me:facs>giallde</me:facs>
<me:dipl>giallde</me:dipl>
<me:norm>gjaldi</me:norm>
</choice>
</w>
<pc>
<choice>
<me:facs>.</me:facs>
<me:dipl>.</me:dipl>
<me:norm></me:norm>
</choice>
</pc>
<supplied reason="restoration" resp="encoder">
<w>
<choice>
<me:facs><am>.ɟ.</am></me:facs>
<me:dipl>halfa</me:dipl>
<me:norm>halfa</me:norm>
</choice>
</w>
<w>
<choice>
<me:facs><am>ᴍ.</am></me:facs>
<me:dipl>mork</me:dipl>
<me:norm>mǫrk</me:norm>
</choice>
</w>
</supplied>
<w>
<choice>
<me:facs>S<am>&er;</am></me:facs>
<me:dipl>S<ex>ilfrs</ex></me:dipl>
<me:norm>silfrs</me:norm>
</choice>
</w>
. . .
An alternative would be to add the presumed abbreviated reading “.ɟ. ᴍ.” in a note, so as to explain why two words of alltogether nine characters have been supplied for this rather small space.
9.4 Editorial comments
Comments are additional text by the editor and not intended to supply or correct the main text. It offers a parallel text stream, linked to the main text when deemed necessary. In print, notes are typically displayed as footnotes or endnotes and thus typographically distinct from the main text. In online texts, notes are often highlighted by colouring or by symbols (such as an asterisk) linked to the relevant reading.
| Elements & attributes | Obl/Opt | Contents |
|---|---|---|
| <note> | Contains comments to the text by the editor. Main attributes: | |
| @type | Optional | Stating what kind of a note it is, e.g. ‘explanation’, ‘variation’, ‘codicology’, ‘paleography’. |
| @source | Optional | Stating the source for a passage in the text, particularly relevant for the ‘variation’ value of the @type attribute. |
These attributes are optional, so it is possible to use the <note> element without any further specification of its contents.
9.4.1 Apparatus-style comments
The apparatus to many printed editions may contain different types of comments, be they of codicological, paleographical or textual nature. If a printed edition is encoded in XML according to the guidelines in this book, some of these notes can be interpreted and rendered by existing elements, such as <sic> + <corr> for any corrections by the editor. Others may be given in the form of notes, which offer a less rigid way of entering the text.
Sometimes an editor may add a “[sic!]” in the apparatus to draw attention to a specific and often unusual form. In these cases, we recommend interpreting this usage by the combination of the <sic> and <corr> elements. If there is no obvious correction, one may add a note stating “highlighted by the editor” or the like.
9.4.2 Explanatory comments
Since so many of the texts in the Menota archive are incomplete, it can be bewildering for users to begin reading a text in medias res, such as Barlaams saga ok Jósafats where the opening is missing in Holm perg 6 fol. In other cases, there will be a break in the text flow, such as that caused by a missing quire in Konungs skuggsjá in AM 243 ba fol. It may also be confusing to see that the numbering of the leaves are in conflict with the text flow, which is the case in Strengleikar in Upps DG 4–7. In these cases, we recommend adding a brief explanatory note. See also the examples of notes in ch. 8.5.2 above.
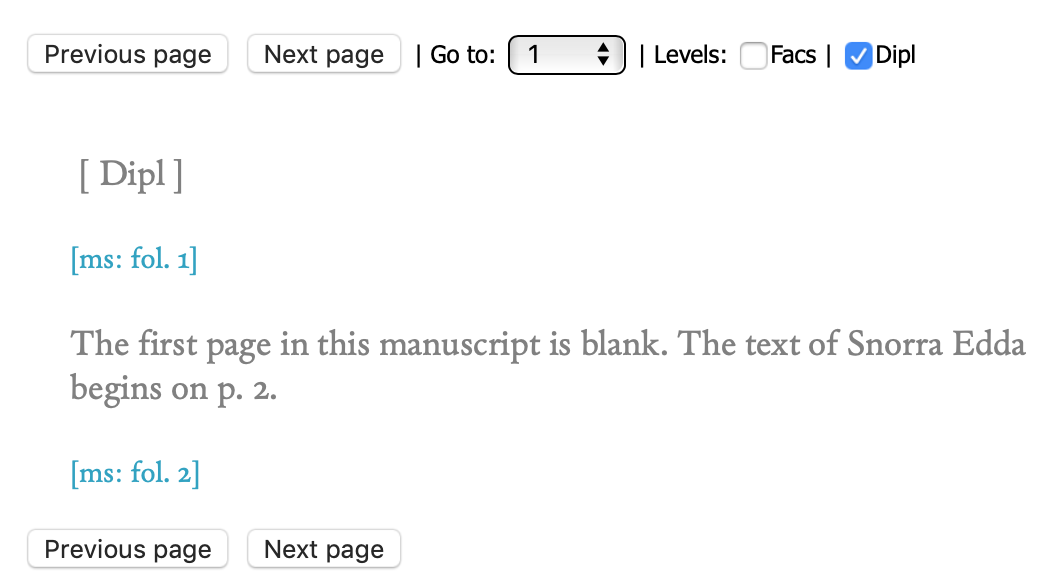
In the Menota archive, the text of Codex Wormianus is opened with a comment stating that the first page is blank. Readers are thus encouraged to move on to the next page:
. . .
<div>
<head>Codex Wormianus: AM 242 fol</head>
<pb ed="ms" n="1"/>
<p>
<note type="explanation">The first page in this manuscript is blank.
The text of Snorra Edda begins on p. 2.</note>
<pb ed="ms" n="2"/>
. . .
</p>
</div>
. . .In the archive, explanatory notes are displayed in the edited text in a light grey colour:
9.4.3 Other types of comments
There are many other types of comments that the transcriber might want to make, such as unusual paleographical traits, variant readings, linguistic peculiarities, etc. See also the EpiDoc Guidelines on “Editor’s Note”.
Updates to ch. 9
On 30 December 2025, ch. 9.2.1 was reorganised so that it was divided into two types of additions, described in ch. 9.2.1.1 and ch. 9.2.1.2 (in the latter, glosses were introduced as another type of scribal addition), and a display of glosses by top left and top right half brackets was proposed in ch. 9.2.1.3.
On 27 April 2020, in ch. 9.3.2.1 the sentence “For this reason, these levels are empty in the example above” was added immediately after “... only the first “sialfr” will be displayed on the diplomatic and normalised levels”. Consequently, the encoding example above was changed so that the <me:dipl> and <me:norm> levels for the second “sialfr” were left empty.
Furthermore, in ch. 9.3.2.2 the following paragraph was added immediately below the text box: “Note that if a word has been deleted on a specific level in a multi-level encoding, such as the second “sjalfr” in ill. 9.12 above, the stylesheet should not display any deletion signs on this level. This is to preclude a display such as “... várr sjalfr {} ok ...”, where the more intuitive display would be “... várr sjalfr ok ...”, suppressing the second “sialfr” silently.”