Ch. 18. Runic inscriptions
Version 4.0 β [last update 26 February 2024]
by Odd Einar Haugen
Important caveat: This chapter is still a draft. It was written by the author for a runic course held in the spring term of 2021, in which a selection of 100 Norwegian inscriptions in younger runes were encoded in XML by the students. The encoding included a representation of each inscription by way of transcription in runes and transliteration into the Latin alphabet, annotation for morphology, various comments, and in many cases new drawings. The corpus is presently accessible on the Menota site: Runic inscriptions catalogue.
The focus for this chapter is the practicalities of encoding runic transcriptions and the contents of the main parts of an XML file (ch. 18.3–18.5). Since the inscriptions in the corpus are dated from c. 980 until the end of the medieval period (following the periods in the Runor project), two stages in the development of the Norwegian runes have been singled out in ch. 18.2, viz. the transitional type from the early 11th century and the medieval type from the late 11th century onwards.
As for other runes, commencing with the older futhark, ch. 18.6 offers an overview of these and a proposal for their encoding. This is very much a draft version, and should not be seen as more than an individual proposal by the author of this chapter. In the autumn of 2023, a Runicode project has been set up, and readers are adviced to follow the development of this project at The Runicode project.
Finally, the author would like to thank colleagues for comments and criticism of this chapter, especially Tor Gjerde (Trondheim).
18.1 Introduction
This chapter deals with the encoding of runic inscriptions. It is based on the selection of runes in the Unicode Runic block, 16A0–16F0. The author is well aware of the criticism levelled against the Unicode Runic block, but one should not underestimate the fact that this is an official standard which will be used by scholars all over the world. For the purpose of encoding runic inscriptions, the selection of runes and their corresponding codepoints in this block should be used whenever possible. This will make it much easier with file sharing and database construction.
In addition to the 81 runic characters in codepoints 16A0–16F0, a number of other runes (or variants of runes) will be presented in ch. 18.6.2 below. They have been assigend to codepoints in the Private Use Area of the Unicode Standard by the author of this chapter – until a broader consensus might be established. Their primary use will be in texts that discuss runes and runic inscriptions, in which the author would like to have specific runic forms represented in print or on screen.
The transcription of runes raises a number of challenges compared with the transcriptions of Latin text in typical codices. In the latter, the writing goes from left to right, line by line, column by column, page by page, and leaf by leaf. Runic inscriptions can begin anywhere on the object, go from left to right or from right to left, and the runes themselves may be turned in at least four prototypical positions – turned once 180° horisontally, once 180° vertically, or a combination of both (i.e. being turned 180° vertically and then 180° horisontally). It is customary to transcribe the runes in a left-to-right direction, and also to render them in their prototypical shape, even if runes usually are turned 180° horisontally if the writing is in the right-to-left direction. For this reason, an encoding of a runic inscription should always be accompanied by a good photograph (often more than one) and, ideally, by a drawing. One might say that a runic transcription will have a higher degree of interpretation than a typical transcription of a text in the Latin alphabet.
There are a number of runic fonts available, and like their Latin counterparts, they have different characteristics. In this chapter, runes will be displayed by a rather simple font developed by the chapter editor, UNI Runes, which would be characterised as a sans serif font if it was made for the Latin alphabet. The great majority of runic fonts are of this type, but it should be mentioned that the font Andron Mega Corpus has runes with serifs. Unfortunately, only a few Unicode compatible runic fonts are available for free; for an overview, see the Wikipedia page Runic (Unicode block).
It is worth noting that the runic glyphs in the Unicode chart are indicative and not normative. This means that even if the runic chart displays an ᚠ 16A0 rune with slighty curved branches, another font might have straight branches for this rune. The contrast between straight and curved branches is non-distinctive, but in order to give the encoders a chance to decide the exact form themselves, this chapter will offer runes with curved as well as straight branches. This means that runes with curved branches have been seen as the default form, whatever the historical merit of this decision. The indicative runes in the Unicode chart leans towards the curved form, but it is difficult to be completely consistent.
We will return to the question of curved vs. straight branches in ch. 18.2.3 and ch. 18.6.2 below, but for now it is important to note that the curved style of branches is regarded as the default shape.
18.1.1 Runic tables
In this chapter, runes will be displayed in tables with five columns. The first shows the actual form of the rune, or “glyph” as it is called in Unicode parlance, the next the transliteration of the rune into the Latin alphabet (more or less equivalent to its supposed sound value), the third the character entity supported by Menota for XML encoded texts, the fourth the hexadecimal codepoint in the Unicode Standard, and the fifth and final column the Menota descriptive name. In all modesty, we believe these names are more transparent than the ones used in the Unicode Runic Block.
For many runes, there is a 1 : 1 correspondence between the rune and its transliteration. There are several exceptions, though, for example for the runes which have the codepoints 16BC, 16C9, 16CB and 16E6. We will return to this problem in greater detail in ch. 18.6 below but would like to draw attention to this stumbling block right from the beginning.
18.1.2 Representation
The three focal levels in Menota are introduced and explained with respect to Latin script in ch. 4 in this handbook. Runic inscriptions can be encoded in a similar way, although the levels will be slightly different with respect to their contents.
On the facsimile level, the inscriptions will be encoded with runic characters as such. This level offers the actual transcription of the runes with as little interpretation as possible.
On the diplomatic level, the inscriptions will be transliterated into the Latin alphabet. Bindrunes will be expanded, and word divisions added (or deleted) where necessary. The orthography will, however, be non-normalised, as is the case with the diplomatic level in texts written in the Latin alphabet.
On the normalised level, the inscriptions will be rendered in standard Old Norse orthography, in the same manner as in Latin script texts. See ch. 10 for the principles behind normalisation.
This is an example of a reading on all three levels. The word elgr ‘elk’ is first rendered in runes, then transliterated into the Latin alphabet and finally normalised:
<w>
<choice>
<me:facs>ᛆᛚᚴᚱ</me:facs>
<me:dipl>alkr</me:dipl>
<me:norm>elgr</me:norm>
</choice>
</w>18.1.3 Annotation
In addition to the three levels of representation, the inscriptions will be annotated for morphology. Each word is listed with its lemma, i.e. the citation form in a dictionary, as well as its morphosyntactic categories, i.e. the grammatical form (case, number, tense, etc.). The lemma and word class are added as attributes to the <w> element:
<w lemma="elgr" me:msa="xNC">
<choice>
<me:facs>ᛆᛚᚴᚱ</me:facs>
<me:dipl>alkr</me:dipl>
<me:norm>elgr</me:norm>
</choice>
</w>The rules for annotation are specified in ch. 11 of the handbook.
18.2 A brief overview of younger Norwegian runes
Introductions in runology tend to list several variants of the younger runic futhark. Among these are the long-branch runes, the short-twig runes, and what can be understood as a transitional type of futhark. The next stage in this development is the medieval runes, discussed in ch. 18.2.2 below.
18.2.1 The Norwegian transitional futhark
The Norwegian transitional futhark was used in the early 11th century and is characterised by containing long-branch as well as short-twig rune forms. It is also known under the rather confusing name “de (eldre) ‘norske’ runer” (NIyR V: 242–243) in spite of being a futhark of younger runes. Michael Barnes opts for “the Norwegian ‘mixed’ futhark” (2012: 61–62), while we have termed it a transitional type of futhark.
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᚠ | f | fGE | 16A0 | GENERAL RUNE F |
| ᚢ | u | uGE | 16A2 | GENERAL RUNE U |
| ᚦ | þ | thGE | 16A6 | GENERAL RUNE THORN |
| ᚮ | o | oYG | 16AE | YOUNGER RUNE O |
| ᚱ | r | rGE | 16B1 | GENERAL RUNE R |
| ᚴ | k | kYG | 16B4 | YOUNGER RUNE K |
| ᚼ | h | hYGL | 16BC | YOUNGER LONG-BRANCH RUNE H |
| ᚿ | n | nYG | 16BF | YOUNGER RUNE N |
| ᛁ | i | iGE | 16C1 | GENERAL RUNE I |
| ᛆ | a | aYG | 16C6 | YOUNGER RUNE A |
| ᛋ | s | sYGL | 16CB | YOUNGER RUNE LONG-BRANCH S |
| ᛌ | s | sYGS | 16CC | YOUNGER RUNE SHORT-TWIG S |
| ᛐ | t | tYG | 16D0 | YOUNGER RUNE T |
| ᛒ | b | bGE | 16D2 | GENERAL RUNE B |
| ᛘ | m | mYGL | 16D8 | YOUNGER RUNE LONG-BRANCH M |
| ᛚ | l | lGE | 16DA | GENERAL RUNE L |
| ᛦ | y | yYG | 16E6 | YOUNGER RUNE Y |
In this row, the only rune for which two variants have been recorded is the s rune, which can have the long-branch shape ᛋ or the short-twig shape ᛌ. Also note that the rune ᛦ is used for the vowel y in this row. It is problematic, perhaps, that the Unicode runic chart has the same codepoint, 16E6, for the rune which in the early period of the younger runes was used for the consonant ʀ (originally a voiced z sound which over time merged with the r sound still used today). After the merger of ʀ and r, there was only a single r rune, ᚱ, so the old ᛦ rune turned out to be a good candidate for the post-Umlaut y vowel. This change of identification was in fact supported by its runic name, ýr. In this overview of the transitional Norwegian futhark, we offer the character entity &yYG; for the y rune.
18.2.2 The Medieval runes
During the late 11th century and throughout the 12th century, the earlier younger futhark was enlarged with a number of additional runic forms, such as ᛂ e, ᛅ æ, ᚯ ø, ᚵ g, d, ᛔ / ᛕ p and ᛋ z. The result is usually referred to as “medieval runes” and often listed in alphabetical order, as here. All of these runes have been included in the official Runic Block of Unicode, but it should be pointed out that the d rune is more commonly seen with the dot between the stave and the branch, , rather than on the stave itself, ᛑ, which is the indicative form chosen by Unicode.
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᛆ | a | aYG | 16C6 | YOUNGER RUNE A |
| ᛒ | b | bGE | 16D2 | GENERAL RUNE B |
| ᛋ | c | cMD | 16CB | MEDIEVAL RUNE C |
| ᛑ | d | dMD | 16D1 | MEDIEVAL RUNE D WITH DOT ON STAVE |
| This variant of the medieval d rune has been selected for display in the Runic table by Unicode, but the variant immediately below should be regarded as the default form in Norwegian inscriptions. In this, the dot is placed between the stave and the branch, as it is in the medieval g rune displayed a few lines further down. | ||||
| | d | dMDdot | F4C2 | MEDIEVAL RUNE D WITH SEPARATE DOT |
| ᛂ | e | eMD | 16C2 | MEDIEVAL RUNE E |
| ᚠ | f | fGE | 16A0 | GENERAL RUNE F |
| ᚵ | g | gMD | 16B5 | MEDIEVAL RUNE G |
| ᚼ | h | hYGL | 16BC | YOUNGER LONG-BRANCH RUNE H |
| ᛁ | i | iGE | 16C1 | GENERAL RUNE I |
| ᚴ | k | kYG | 16B4 | YOUNGER RUNE K |
| ᛚ | l | lGE | 16DA | GENERAL RUNE L |
| ᛘ | m | mYGL | 16D8 | YOUNGER RUNE LONG-BRANCH M |
| ᚿ | n | nYG | 16BF | YOUNGER RUNE N |
| ᚮ | o | oYG | 16AE | YOUNGER RUNE O |
| ᛔ | p | pMD | 16D4 | MEDIEVAL RUNE P |
| ᛕ | p | pMDopen | 16D5 | MEDIEVAL RUNE OPEN P |
| ᛩ | q | qMD | 16E9 | MEDIEVAL RUNE Q |
| ᚱ | r | rGE | 16B1 | GENERAL RUNE R |
| ᛌ | s | sYGS | 16CC | YOUNGER RUNE SHORT-TWIG S |
| ᛍ | s | sYGSdot | 16CD | YOUNGER RUNE SHORT-TWIG S WITH DOT |
| ᛐ | t | tYG | 16D0 | YOUNGER RUNE T |
| ᚦ | þ | thGE | 16A6 | GENERAL RUNE THORN |
| ᚢ | u | uGE | 16A2 | GENERAL RUNE U |
| ᚼ | x | xMDhtyp | 16BC | MEDIEVAL RUNE H-TYPE X |
| ᛪ | x | xMDstyp | 16EA | MEDIEVAL RUNE S-TYPE X WITH STROKES |
| ᛦ | y | yYG | 16E6 | YOUNGER RUNE Y |
| ᚤ | y | yMD | 16A4 | MEDIEVAL RUNE DOTTED U |
| ᛋ | z | zMD | 16CB | MEDIEVAL RUNE Z |
| ᛎ | z | zMDsht | 16CE | MEDIEVAL RUNE SHORT Z |
| ᛅ | æ | aeMD | 16C5 | MEDIEVAL RUNE AE |
| ᚯ | ø | oeMD | 16AF | MEDIEVAL RUNE O SLASH |
| ᚰ | ǫ | oeMDsht | 16B0 | MEDIEVAL RUNE O SLASH SHORTENED |
The final rune above is a variant of the preceding one, ᚯ, in which one of the branches has been shortened. There are in fact four variants of this rune, depending on which branch has been shortened on which side of the main stave; see ch. 18.6.2 for the full repertoire of possible variants. The rune is usually transliterated by an “o ogonek”, ‘ǫ’, even if it in several cases should have been transliterated by ‘ø’ (see Seim 2013: 174 first paragraph, and Barnes 2012: 94). However, since it will be practical to distinguish ᚰ from ᚯ and since it sometimes had the sound value of ‘ǫ’, the descriptive name is given as MEDIEVAL RUNE O SLASH SHORTENED, the character entity as &oeMDsht; and the proposed transliteration character as ‘ǫ’. The descriptive name thus focuses on the graphical form of the rune, rather than its possible sound value. In the character entity &oeMDsht;, “sht” is an abbreviation of ‘short(ened)’, as in 16CE above.
18.2.3 The runes of NIyR
As stated in 18.1, the default form of the runes in this chapter is the one with curved branches. This is what the medieval runes would look like, in alphabetical order:
ᛆ ᛒ ᛑ ᛂ ᚠ ᚵ ᚼ ᛁ ᚴ ᛚ ᛘ ᚿ ᚮ ᛔ (or ᛕ) ᚱ ᛌ (or ᛋ or ) ᛐ ᚦ ᚢ ᛦ ᛅ ᚯ ᚰ
In the corpus edition of younger Norwegian runes, Norges innskrifter med de yngre runer, there is, however, a mixture of curved and straight branches (cf. vol 5, pp. 238–245, especially p. 244). This is the NIyR style of the younger Norwegian runes:
ᛆ ᛒ ᛂ ᚼ ᛁ ᛚ ᚿ ᚮ ᛔ (or ᛕ) ᚱ ᛌ (or ᛋ or ) ᛐ ᚦ ᚢ ᛅ ᚯ ᚰ
It should be left to the encoders to decide whether the feature of curvature should be adhered to in the encoding and display of runes. What is offered in this chapter, is the possibility to encode runes so that the NIyR style is preserved. The straight runes f, g, k, m and y then have to be encoded specifically using the character entities listed in ch. 18.6.2 below.
In the forthcoming OpenType font UNI Runes, the NIyR style can be selected by a stylistic set. This means that the runes can be encoded in the default style with curved branches, and that the NIyR style can be implemented by a single stylistic set.
18.3 Transcription rules
In the runic community, there are some quite specific transcription conventions, as detailed in the Runor database. See the section “Specialtecken och textkritiska konventioner” for a summary of these rules. In this chapter, we aim to deal with the cases covered by these conventions, although with a view to the practice of encoding and displaying texts in the Latin alphabet.
Our primary concern will be the actual XML encoding, for example that illegible runes should be encoded with the <unclear> element. The display, in editions or websites, is of secondary importance. According to the Menota guidelines, illegible characters, whether they are runes or Latin letters, should preferably be displayed with a dotted circle (cf. ch. 8.4.1). In some runic conventions, like those underlying NIyR, an asterisk will be used instead. The actual display is a matter for the stylesheets being used, and is an independent and secondary decision compared to the actual encoding.
18.3.1 Rows and lines
We should probably identify each inscription in a single <pb/> element. If there are more than one inscription on an object, they have either to be treated as individual inscriptions, each recorded in its own file, or as instances of more than one <pb/> element. This might be the case if the inscriptions seem to form a semantic or pragmatic whole. In general, the signum given to the inscription should be taken as indicative of its status.
If the inscription has more than one line, this should be declared by the <lb/> element, which specifies the beginning of a line. This element should be used even if there is only a single line in the inscription.
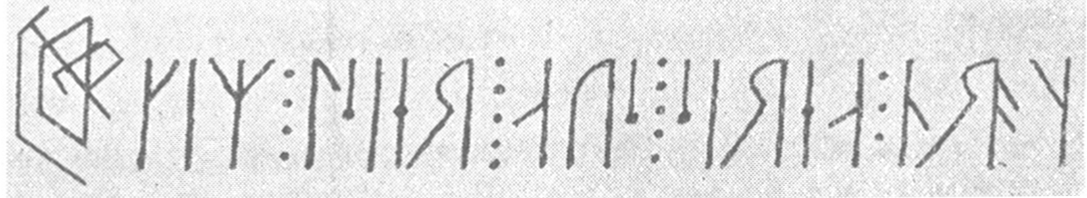
Ill. 18.1 (a). Inscription running from the right to the left. The final symbol is probably a monogram in Latin letters of CORE, the name of the rune carver. This reads from left to right. || N 146 (Gåra demolished stave church, Bø in Telemark). Scanned from NIyR.
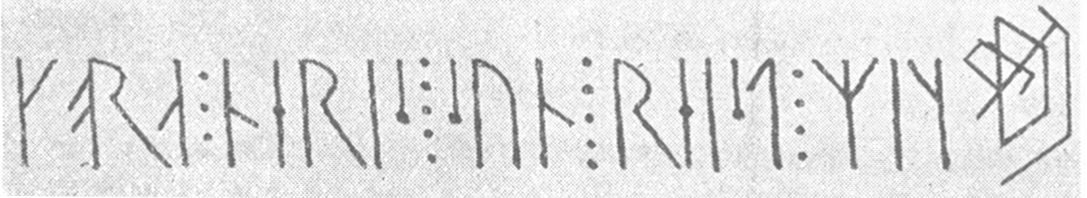
Ill. 18.1 (b). N 146 flipped horisontally. Note that the branches are now located in their usual position with the exception of the very last rune. This was perhaps kept in its reversed form so that it mirrored the first ᚴ k rune.
A number of inscriptions (or parts of inscriptions) are carved from the right to the left, such as N 146 in ill. 18.1 (a). We recommend that the transcription is rendered from the left to the right, i.e. in the ordinary direction of reading. The direction of carving should be noted in a comment, though, and an illustration added if possible, perhaps flipped, like ill. 18 (b), so as to make it easier to read.
18.3.2 Words and word divisions
On the facsimile level, an inscription should be transcribed “as is”, even if it is a continuous string of what obviously is more than one word. On the diplomatic level, we recommend that the inscription is grouped into words (which can be annotated for lemma and grammatical form), and the same goes for the normalised level.
From a practical point of view, this can be attained by dividing the whole string of runes into <w> elements on all three levels, but by using the <seg> element on the facsimile level to show the lack of word boundaries.

Ill. 18.2. Scriptio continua: Four words written without any word division. || N 42 (Lom stave church). Scanned from NIyR.
In N42 (Lom stave church) the second line of the inscription is carved without any word divisions, ᚼᚢᛆᚱᚼᛂᛍᛁᛘᚼᛆᚿᚠᛅᚱ huarhesimhanfær, normalised hvargi sem hann ferr “wherever he may travel”. In the transcription, the four distinct words have been encoded in individual <w> elements, and the whole sequence in a <seg> element epcified by a @type attribute with the ‘nb’ value for “no break”:
<seg type="nb">
<w>
<choice>
<me:facs>ᚼᚢᛆᚱᚼᛂ</me:facs>
<me:dipl>huarhe</me:dipl>
<me:norm>hvargi</me:norm>
</choice>
</w>
<w>
<choice>
<me:facs>ᛍᛁᛘ</me:facs>
<me:dipl>sim</me:dipl>
<me:norm>sem</me:norm>
</choice>
</w>
<w>
<choice>
<me:facs>ᚼᛆᚿ</me:facs>
<me:dipl>han</me:dipl>
<me:norm>hann</me:norm>
</choice>
</w>
<w>
<choice>
<me:facs>ᚠᛅᚱ</me:facs>
<me:dipl>fær</me:dipl>
<me:norm>ferr</me:norm>
</choice>
</w>
</seg>Sometimes, a whole inscription is written without word divisions, like B 390 and N 358, and in other cases one or more parts, like N 42 and N 68.
The converse case is represented by words split into two or more components. One example is found in N 531 (Borgund stave church) which has the compund word ᚮᛚᛆᚢᛌ · ᛘᛂᛌᛌᚮ · ᛅᛕᚦᛆᚿ olaus · messo · æpþan, i.e. óláfsmessuaftann, as can be seen in ill. 18.3.

Ill. 18.3. Detail showing the final two words in line 1, þan · olaus · messo · æpþan. Due to the height of the staves and the diminutive branches the runes in this inscription are not easily read. || N 351 (Borgund stave church). Drawing by Saskia J. Cowan (2021).
In preparation for morphological annotation, the latter word should be encoded within a single <w> element:
<w>
<choice>
<me:facs>ᚦᛆᚿ</me:facs>
<me:dipl>þan</me:dipl>
<me:norm>þann</me:norm>
</choice>
</w>
<pc type="runic">
<choice>
<me:facs>·</me:facs>
<me:dipl>·</me:dipl>
<me:norm></me:norm>
</choice>
</pc>
<w>
<choice>
<me:facs>ᚮᛚᛆᚢᛌ <pc>·</pc> ᛘᛂᛌᛌᚮ <pc>·</pc> ᛅᛕᚦᛆᚿ</me:facs>
<me:dipl>olaus <pc>·</pc> messo <pc>·</pc> æpþan</me:dipl>
<me:norm>óláfsmessuaftann</me:norm>
</choice>
</w>Note that the punctuation marks are rendered with the <pc> element within the single <w> element. Also note that the encoding above is slightly simplified, since the latter word has two bind-runes, one of ᚮᛅ oæ and one of ᛆᚿ an. See ch. 18.3.3 below for the encoding of bind-runes.
For more details on words and their delimitation, see ch. 5.3 above.
18.3.3 Bind-runes
Bind-runes should be encoded by the <seg> element, as specified in ch. 5.3.1 above:
| Elements & attributes | Obl/Opt | Explanation |
|---|---|---|
| <seg> | Groups one or more segments of characters. | |
| @type | Obligatory | States the type of segmentation. Suggested value: |
| ‘lig’ | Bind-rune (i.e. a ligature) | |
| ‘lig-initial’ | The first part of a bind-rune | |
| ‘lig-final’ | The final part of a bind-rune |
In the majority of cases, bind-runes are located within a single lexical word. In some cases, a bind-rune will cross a word boundary, which makes for a more challenging encoding. We discuss both types below.
1. Bind-runes within a word
The first word in 146, ill. 18.1 (b)above, contains a bind-rune of ᚮ o and ᚱ r, in which the two runes share the vertical stave. Other incriptions may contain many more bind-runes, such as N 446, Tingvoll church. The three words in ill. 18.4 have no less than four bind-runes.
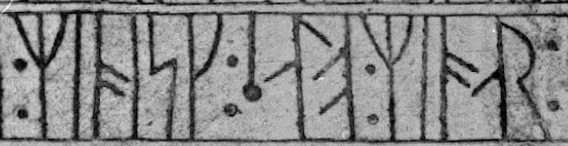
Ill. 18.4. Four bind-runes in three words. || N 446 (Tingvoll church, Nordmøre), 3rd line. Scanned from NIyR.
Note that the bind-rune of ᚿᚿ nn is a stave with two branches, one from each rune. The encoding is this:
<w>
<choice>
<me:facs>ᛘᛁ<seg type="lig">ᚿᚿ</seg>ᛁᛋᚴ</me:facs>
<me:dipl>mi<seg type="lig">nn</seg>izk</me:dipl>
<me:norm>minnisk</me:norm>
</choice>
</w>
<pc type="runic">
<choice>
<me:facs>:</me:facs>
<me:dipl>:</me:dipl>
<me:norm></me:norm>
</choice>
</pc>
<w>
<choice>
<me:facs>ᛍ<seg type="lig">ᛆᛚ</seg>ᚮ</me:facs>
<me:dipl>s<seg type="lig">al</seg>o</me:dipl>
<me:norm>sálu</me:norm>
</choice>
</w>
<pc type="runic">
<choice>
<me:facs>:</me:facs>
<me:dipl>:</me:dipl>
</choice>
</pc>
<w lemma="minn" me:msa="xDP nS gF cG">
<choice>
<me:facs>ᛘᛁ<seg type="lig">ᚿᚿ</seg><seg type="lig">ᛆᚱ</seg></me:facs>
<me:dipl>mi<seg type="lig">nn</seg><seg type="lig">ar</seg></me:dipl>
<me:norm>minnar</me:norm>
</choice>
</w>From a graphical point of view, the bind-rune ᚭ of ᚿᚿ nn is identical with the short-twig rune for nasal a, ᚭ ã, but from the context it is clear that it must be read as nn.
The majority of bind-runes are ligatures of two runes, but there are also examples of bind-runes of three runes, e.g. in B 493, in which the conjunction auk ‘and’ is carved with a single bind-rune.
<w>
<choice>
<me:facs><seg type="lig">ᛆᚢᚴ</seg></me:facs>
<me:dipl><seg type="lig">auk</seg></me:dipl>
<me:norm>ok</me:norm>
</choice>
</w>2. Bind-runes across word boundaries
If a bind-rune crosses a word boundary and the inscription is divided into <w> elements, due to limitations in XML it is not possible to encode the bind-rune within a single <seg> element spanning from one word to the next. We recommend using two <seg> elements with the @type attribute specifying which word the bind-rune belongs to by a ‘lig-initial’ value for the first part of the bind-rune and a ‘lig-final’ value for the second part of the bind-rune.

Ill. 18.5. Bind-rune across a word boundary. The fifth rune is evidently ᚢ, but it has the branch of the ᛆ rune, too, so it must be read as a bind-rune ᛆᚢ. || B 192 (from the Runic archives, Oslo).
In B 192 (Bryggen in Bergen) the first word is ᛍᛚᛁᚴᛆ slika and the second ᚢᛁᛚᛐᛆ uilta, and there is a bind-rune made up of ᛆ in the first word and ᚢ in the second. We suggest the following encoding:
<seg type="nb">
<w>
<choice>
<me:facs>ᛍᛚᛁᚴ<seg type="lig-initial">ᛆ</seg></me:facs>
<me:dipl>slik<seg type="lig-initial">a</seg></me:dipl>
<me:norm>Slíka</me:norm>
</choice>
</w>
<w>
<choice>
<me:facs><seg type="lig-final">ᚢ</seg>ᛁᛚᛐᛆ</me:facs>
<me:dipl><seg type="lig-final">u</seg>ilta</me:dipl>
<me:norm>vilda</me:norm>
</choice>
</w>
</seg>Bind-runes are usually displayed by an inverted combining breve. The bind-rune of ᛆ and ᚢ is thus displayed as ᛆᚢ. If the bind-rune crosses a word boundary (as encoded by the ‘lig-final’ and ‘lig-initial’ values), it will be displayed by a half inverted breve, i.e. ᛆ and ᚢ respectively. If the bind-rune is made up of three runes, a longer inverted breve will be used, e.g. ᛆᛁᚢ.
18.3.4 Shared runes across word boundaries
In the runic inscription N 393 (Hopperstad stave church, Sogn), the graphical word “þæimane” must be interpreted as “þeim|manni” ‘for this man’, in which the “m” rune is shared between two words.

Ill. 18.6. Rune which is shared between two words. || N 393 (Hopperstad church), 2nd line. The two final words in this line have been highlighted in red.
We recommend that this type of overlap is encoded by the <seg> and <c> elements:
| Elements & attributes | Obl/Opt | Explanation |
|---|---|---|
| <seg> | Groups one or more segments of text, e.g. words. | |
| @type | Obligatory | States the type of segmentation. Suggested value: |
| ‘nb’ | No break | |
| <c> | Contains an individual character. | |
| @type | Obligatory | Type of character. Suggested values: |
| ‘dupl’ | The character is a duplicated, i.e. used in two consecutive words. |
The Menota encoding would look like this:
<seg type="nb">
<w>
<me:facs>ᚦᛅᛁ<c type="dupl">ᛘ</c></me:facs>
<me:dipl>þæi<c type="dupl">m</c></me:dipl>
<me:norm>þeim</me:norm>
</w>
<w>
<me:facs><c type="dupl">ᛘ</c><seg type="lig">ᛆᚿ</seg>ᛂ</me:facs>
<me:dipl><c type="dupl">m</c><seg type="lig">an</seg>e</me:dipl>
<me:norm>manni</me:norm>
</w>
</seg>This orthography is peculiar to runic writing and can be seen partly as a consequence of the tendency to denote geminates by single runes and partly as a consequence of scriptio continua.
18.3.5 Unclear and illegible runes
Unclear runes should be encoded by the <unclear> element as specified in ch. 8.4.1 above. Note that a distinction should be drawn between a rune which is unclear, but still readable, and a rune which simply cannot be read with any degree of certainty. While it is possible to specify the degree (e.g. in a percentage) of readability, we suggest to make a simple distinction between these basic types, i.e. unclear runes and illegible runes.
| Elements & attributes | Obl/Opt | Contents |
|---|---|---|
| <unclear> | Contains a character, word, phrase or passage which cannot be transcribed with certainty. | |
| @reason | Optional | Indicates why the material is hard to transcribe. Sample values include: ‘faded’, ‘weathered’, ‘smudged’, ‘erased’. |
In N 121 (Ål church, Hallingdal), two names have probably been carved in the middle of the second line, as can be seen from the detail in ill. 18.7. The first name is clearly ᛅᛁᚱᛁᚴᚱ æirikr, while the second name probably has an initial ᚴ k rune and a final bind-rune ᛆᚱ ar. The two or three intermediate runes must be regarded as illegible, even if one possibly can see the top of a ᚢ u rune here.
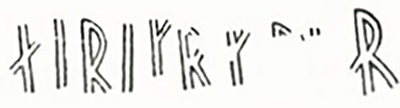
Ill. 18.7. Illegible runes. || N 121 (Ål church), detail. Scanned from NIyR.
We recommend using the <unclear> element with “place holders” for the illegible runes, such as the DOTTED CIRCLE at U+25CC or, adhering to the conventions in NIyR, by asterisks – one for each illegible rune:
<w>
<choice>
<me:facs>ᛅᛁᚱᛁᚴᚱ</me:facs>
<me:dipl>æirikr/me:dipl>
<me:norm>Eiríkr</me:norm>
</choice>
<w>
<choice>
<me:facs>ᚴ<unclear reason="weathered">**</unclear><seg type="lig">ᛆᚱ</seg></me:facs>
<me:dipl>k<unclear reason="weathered">**</unclear><seg type="lig">ar</seg></me:dipl>
<me:norm>k<unclear reason="weathered">**</unclear><seg type="lig">ar</seg></me:norm>
</choice>
</w>If the editor would like to make a conjecture about the illegible runes, this can be done by the <supplied> element, as suggested in ch. 18.3.9 below. In this case, it is likely that the partly illegible name was ᚴᚢᚿᛆᚱ kunar, normalised Gunnarr. The encoding would be:
<w>
<choice>
<me:facs>ᛅᛁᚱᛁᚴᚱ</me:facs>
<me:dipl>æirikr/me:dipl>
<me:norm>Eiríkr</me:norm>
</choice>
<w>
<choice>
<me:facs>ᚴ<unclear reason="weathered">**</unclear><seg type="lig">ᛆᚱ</seg></me:facs>
<me:dipl>k<supplied reason="restoration">un</supplied><seg type="lig">ar</seg></me:dipl>
<me:norm>G<supplied reason="restoration">unn</supplied>arr</me:norm>
</choice>
</w>The display of unclear runes can be with a grey colour or by a dot below. See ch. 8.4.2 for details.
18.3.6 Added runes
Runes added by the carver (or in the case of a codex, the scribe) should be encoded by the <add> element as specified in ch. 9.2.1.1 above.
| Elements & attributes | Obl/Opt | Contents |
|---|---|---|
| <add> | Contains characters, words or phrases added to the inscription by the carver, whether in the same hand or in a later hand. Attributes include: | |
| @place | Obligatory | Indicates where the addition is made. Suggested values include ‘inline’, ‘supralinear’, ‘infralinear’ and ‘margin’. |
| @hand | Optional | Signifies the carver who made the addition. Sample values may be ‘carver’, ‘maincarver’ and ‘latercarver’. |

Ill. 18.8 (a). Inscription with an added rune. || N 57 (Ringebu stave church), displayed in its original direction of writing, from the right to the left. Note the high degree of bind-runes in this graffiti-like inscription. Scanned from NIyR.

Ill. 18.8 (b). N 57 flipped horisontally. The branches are now pointed in their usual direction.
In the example from N 57, the rune ᚼ h has been added above the line in the word “han”. Note that there is no word division, hence the use of the <seg> element:
<seg type=nb">
. . .
<w>
<choice>
<me:facs><add place="supralinear">ᚼ</add>ᛆᚿ</me:facs>
<me:dipl><add place="supralinear">h</add>an</me:dipl>
<me:norm>hann</me:norm>
</choice>
</w>
<w>
<choice>
<me:facs>ᚢ<supplied reason="emendation">ᛐ</supplied></me:facs>
<me:dipl>u<supplied reason="emendation">t</supplied></me:dipl>
<me:norm>ú<supplied reason="emendation">t</supplied></me:norm>
</choice>
</w>
</seg>The display of added runes is usually made by insertion markers. See ch. 9.2.1.2 for details.
18.3.7 Deleted runes
Runes deleted by the carver (or in the case of a codex, the scribe) should be encoded by the <del> element as specified in ch. 9.2.2.1 above.
| Elements & attributes | Obl/Opt | Contents |
|---|---|---|
| <del> | Contains a character, word or passage deleted or otherwise indicated as superfluous or spurious by the carver. Attributes include: | |
| @rend | Obligatory | This attribute is used to classify the deletion, using any convenient typology. Sample values include ‘overstrike’, ‘erasure’ and ‘subpunction’. |
| @hand | Optional | Signifies the scribe who made the deletion. Values include ‘carver’, ‘maincarver’ and ‘latercarver’. |
Deleted runes are less common than deleted characters in manuscripts; there was no tradition for subpunction for example in runic writing. One example of deletion is probably found in N 291 (Bryggen in Bergen), in which the carver seems to have deleted a bind-rune by adding another branch to the stave, so as to make it into a non-existent rune.

Ill. 18.9. Deletion of a rune by adding an unnecessary branch. || N 291 (Bryggen in Bergen) in which the highlighted rune probably should be read as a deletion of the bind-rune ᚮᚴ ok.
Magnus Olsen suggest that the rune carver decided to replace the conjunction ᚮᚴ ok with the ensuing conjunction ᛂᚿ en, and for this reason he added another branch to the stave of ᚮ o, so as to make it into a non-existent rune (NIyR IV, 55). This process could be seen as a kind of overstrike. The encoding would be:
<w>
<choice>
<me:facs>ᛘᛁᚵ</me:facs>
<me:dipl>mig</me:dipl>
<me:norm>mik</me:norm>
</choice>
</w>
</w>
<choice>
<me:facs><del><seg type="lig">ᚮᚴ</seg></del></me:facs>
<me:dipl><del><seg type="lig">ok</seg></del></me:dipl>
<me:norm><del>ok</del></me:norm>
</choice>
</w>
<w>
<choice>
<me:facs>ᛂᚿ</me:facs>
<me:dipl>en</me:dipl>
<me:norm>en</me:norm>
</choice>
</w>In this particular inscription, the dotted ᚵ rune was used several times for k rather than g.
The display of deleted runes is usually by vertical bars with quills. See ch. 9.2.2.2 for details.
18.3.8 Substituted runes
If the carver (or in codices, the scribe) substitutes one rune for another rune in the same position, we recommend that this action is encoded with a combination of the <del> and the <add> elements, as specified in ch. 9.2.4 above.

Ill. 18.10. Substitution of one rune for another. || AM 28 8vo (Codex Runicus), fol. 3r, line 3.
In ill. 18.10, the scribe has probably written the middle word as ᚵᛁᚵᛅ gigæ and then corrected it to ᚵᛁᚠᛅ gifæ, as can be seen from the difference in the colour of the ink. He has probably decided to strengthen the three other runes in this word at the same time. This would be the encoding:
<w>
<choice>
<me:facs>ᚢᛁᛚ</me:facs>
<me:dipl>uil</me:dipl>
<me:norm>vil</me:norm>
</choice>
</w>
</w>
<choice>
<me:facs>ᚵᛁ<del>ᚵ</del><add>ᚠ</add>ᛅ</me:facs>
<me:dipl>gi<del>g</del><add>f</add>æ</me:dipl>
<me:norm>gefa</me:norm>
</choice>
</w>
<w>
<choice>
<me:facs>ᚦᛅᛘ</me:facs>
<me:dipl>þæm</me:dipl>
<me:norm>þeim</me:norm>
</choice>
</w>Note that this example is from Old Danish, for which there is no single normalised orthography. In the example above, Old Norse normalised orthography has been used on the normalised level, which is purely experimental.
See ch. 9.2.2.2 and ch. 9.2.1.2 above for the display of deleted and added runes. A consequence of this encoding is that the operation of deleting and adding is displayed subsequently on the <me:facs> and <me:dipl> levels, while the intended form is displayed on the <me:norm> level.
18.3.9 Supplied runes
Runes supplied by the modern editor should be encoded by the <supplied> element as specified in ch. 9.3.1 above.
| Elements & attributes | Obl/Opt | Contents |
|---|---|---|
| <supplied> | Signifies text supplied by the editor in order to restore or emend the inscription. Attributes include: | |
| @reason | Obligatory | Indicates why the inscription has been supplied. It should be given one of the two values, ‘restoration’ or ‘emendation’. The former covers text which is lost through damage or left empty by intention, text which is unclear, and text which is simply illegible. The latter covers editorial enhancement with respect to grammar, lexicon, syntax, context or the like. |
| @resp | Obligatory | Indicates the individual responsible for the addition of characters, words or passages contained within the <supplied> element. |
| @source | Optional | States the source of the supplied text if this can be located. |
1. Restoration
Supplying a piece of text will be regarded as a restoration if the text has been left empty by intention, if it is unclear or if it simply is illegible. In N 540 (a ring from Botnhamn, Senja), the final, illegible rune in the first word has been encoded with the <unclear> element on the facsimile level (as recommended in ch. 18.3.5 above), while the rather obvious conjecture of the ᛘ m rune, has been entered on the diplomatic and normalised levels. This has been done in the <supplied> element specified by the @reason attribute with the ‘restoration’ value:
<w>
<choice>
<me:facs>ᚠᚢᚱᚢ<unclear reason="damage">*</unclear></me:facs>
<me:dipl>furu<supplied reason="restoration" resp="AslakLiestol">m</supplied></me:dipl>
<me:norm>fóru<supplied reason="restoration" resp="AslakLiestol">m</supplied></me:norm>
</choice>
</w>A more extensive example is found in N 564 (Høre church, Valdres), in which the final three runes in the first word of ill. 18.11 are only partly readable. The two first runes are ᛍᚢ, and from the context, it seems likely that the three next runes were ᛘᛆᚱ, thus making the word ᛍᚢᛘᛆᚱ sumar, ‘summer’. Aslak Liestøl should be credited with this interpretation.
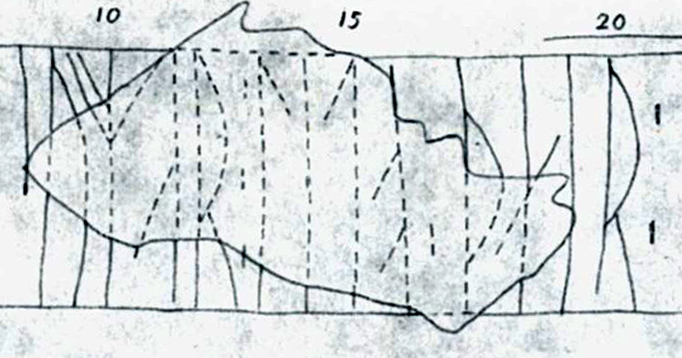
Ill. 18.11. Restoration of runes. || N 564 (Høre church). Scanned from NIyR.
The final three runes will be encoded by the <unclear> element on the facsimile level and restored in the <supplied> element on the diplomatic and normalised levels:
<w>
<choice>
<me:facs>ᛍᚢ<unclear reason="damage">ᛘᛆᚱ</unclear></me:facs>
<me:dipl>su<supplied reason="restoration" resp="AslakLiestol">mar</supplied></me:dipl>
<me:norm>su<supplied reason="restoration" resp="AslakLiestol">mar</supplied></me:norm>
</choice>
</w>The next word in the inscription is completely damaged and illegible. From the extent of it, it probably had four runes. We cannot tell for sure which word it was, but a convincing case can be made for the verb form létu of láta, ‘let’. This word will be encoded by the <unclear> element on the facsimile level and restored in the <supplied > element on the diplomatic and normalised levels:
<w>
<choice>
<me:facs><unclear reason="damage">****</unclear></me:facs>
<me:dipl><supplied reason="restoration" resp="AslakLiestol">leto</supplied></me:dipl>
<me:norm><supplied reason="restoration" resp="AslakLiestol">létu</supplied></me:norm>
</choice>
</w>The display of restored text is usually by way of square brackets. For details, see see ch. 9.3.1.1 and ch. 9.3.1.3 above.
2. Emendation
If there is a piece of text which the editor think is missing for lack of syntactic, pragmatic or semantic congruity, even if no trace of it can be found in the source, this text may be added by way of the <supplied> element. This would be regarded as an emendation, which should be stated by way of the @reason attribute with the ‘emendation’ value.

Ill. 18.12. Emendation of ᛂᛐ et to ᚼᛂᛐ het. || N 446 (Tingvoll church, Nordmøre), detail from the opening of the 4th line.
In N446, the second word in ill. 18.12 reads ᛂᛐ et. This is a preterite form of the verb heita spelt with h-dropping, so a modern editor might want to emend it from “ét” to “hét”:
<w>
<choice>
<me:facs>ᛆᛚᚴ</me:facs>
<me:dipl>ek</me:dipl>
<me:norm>ek</me:norm>
</choice>
</w>
<w>
<choice>
<me:facs>ᛂᛐ</me:facs>
<me:dipl><supplied reason="emendation" resp="editor">h</supplied>et</me:dipl>
<me:norm><supplied reason="emendation" resp="editor">h</supplied>ét</me:norm>
</choice>
</w>
<w>
<choice>
<me:facs>ᚵᚢ<seg type="lig">ᚿᚿ</seg><seg type="lig">ᛆᚱ</seg></me:facs>
<me:dipl>gu<seg type="lig">nn</seg><seg type="lig">ar</seg></me:dipl>
<me:norm>Gunnarr</me:norm>
</choice>
</w>The display of emended text is usually by way of open angle brackets. For details, see ch. 9.3.1.2 and ch. 9.3.1.3 above.
18.3.10 Suppressed text
From time to time, the transcriber may want to suppress text which for some reason or another seems superfluous. In manuscripts, dittographies are frequent examples of superfluous text, but possibly less so in runic inscriptions. The suppressed text should be encoded on the facsimile level, but may be deleted on the diplomatic and normalised levels. The <surplus> element should be used in all cases of editorial suppression:
| Elements & attributes | Obl/Opt | Explanation |
|---|---|---|
| <surplus> | Contains text which the editor believes should be recognised as superfluous. | |
| @reason | Optional | Type of superfluous text. Suggested values: |
| ‘dittography’ | Text which is written twice in a row. | |
| ‘excess’ | Text which is unnecessary for grammatical, semantic or pragmatic reasons. |
The inscription N 351 (Borgund) has a single runic character ᚵ g in the opening of the 4th line. Immediately afterwards, skapaþu ‘created, made’ is written, as can be seen in ill. 18.13.

Ill. 18.13. Suppression of a runic character. N 351 (Borgund stave church), the 4th line. Drawing by Saskia J. Cowan (2021).
Magnus Olsen suggests that the carver had intended to write gerþo, but thought better of it since he had used this word in the line above, and therefore changed to the equivalent skapaþu. The g thus became superfluous, and is a candidate for suppression:
<surplus reason="excess">
<choice>
<me:facs>ᚵ</me:facs>
<me:dipl></me:dipl>
<me:norm></me:norm>
</choice>
</surplus>
<w>
<choice>
<me:facs>ᛍᚴᛆᛕᛆᚦᚢ</me:facs>
<me:dipl>skapaþu</me:dipl>
<me:norm>skǫpuðu</me:norm>
</choice>
</w>
<seg type="nb">
<w>
<choice>
<me:facs>ᚦᛅᚱ</me:facs>
<me:dipl>þær</me:dipl>
<me:norm>þǽr</me:norm>
</choice>
</w>
<w>
<choice>
<me:facs>ᛘᛂᚱ</me:facs>
<me:dipl>mer</me:dipl>
<me:norm>mér</me:norm>
</choice>
</w>
</seg>For details, see ch. 9.3.2 above.
18.3.11 Latin characters
Latin characters in an inscription which otherwise has runic characters should be encoded with the <c> element as specified in ch. 5.2.3 above:
| Elements & attributes | Obl/Opt | Explanation |
|---|---|---|
| <c> | Contains an individual character. | |
| @type | Obligatory | Type of character. Suggested values: |
| ‘latin’ | The character is in the Latin alphabet. |

Ill. 18.14. Mixture of runes and Latin characters || Detail from the cover of the Kvikne psalter (N 553).
The inscription N 553 is found on the wooden cover of a Latin psalter from Kvikne church in Tynset, Innlandet. It is carved in a rather unusual mixture of Latin minuscles and runic characters, stating that the psalter is owned by Kvikne church:
<w>
<choice>
<me:facs><c type="latin">kuik</c>ᚿᛆ</me:facs>
<me:dipl>kuikna</me:dipl>
<me:norm>Kvikna</me:norm>
</choice>
</w>
<w>
<choice>
<me:facs><c type="latin">kk</c>ᛆ</me:facs>
<me:dipl>k<supplied reason="restoration">ir</supplied>k
<supplied reason="restoration">i</supplied>a</me:dipl>
<me:norm>kirkja</me:norm>
</choice>
</w>
<w>
<choice>
<me:facs>ᛆ</me:facs>
<me:dipl>a</me:dipl>
<me:norm>á</me:norm>
</choice>
</w>
<w>
<choice>
<me:facs><unclear>*</unclear>ᛁᚴ</me:facs>
<me:dipl><supplied reason="restoration">m</supplied>ik</me:dipl>
<me:norm>mik</me:norm>
</choice>
</w>In some cases, it may difficult to decide whether a certain character is a rune or a Latin capital, e.g. with respect to the B and R characters.
18.3.12 Lost runic text
Lost runic text should be encoded with the <gap/> element as specified in ch. 8.2.1 above. Note that the <gap/> element is an empty element, as stated by the concluding slash. If there are attributes to the element, e.g. <gap quantity="2" unit="char"/>, note that the slash is placed at the very end.
| Elements & attributes | Obl/Opt | Contents |
|---|---|---|
| <gap/> | Is an element without extention in the encoded inscription. It indicates a point where material has been omitted in a transcription because it is physically missing in the inscription. Attributes include: | |
| @unit | Obligatory | Names the unit used for describing the extent of the gap. Values will typically be ‘char’ (character), ‘word’, ‘line’, or even ‘indeterminate’. |
| @quantity | Optional | Indicates approximately how much text has been omitted from the inscription. Values can be given as e.g. number of characters, words or lines, i.e. ‘1’, ‘2’, ‘3’, etc. Note that only numbers are accepted as values; the category is described in the @unit attribute. If the extent of the gap is described as ‘indeterminate’ in the @unit attribute, it does not make sense to try and specify a quantity. |
| @reason | Optional | Gives the reason for omission. Sample values include: ‘damaged’, ‘cut’, ‘missing’. |
In some cases, it is impossible for the editor to estimate the size of the lost text and also to make any conjecture of what has been lost. The @unit attribute may then be left with the ‘indeterminate’ value, and there is no reason to try and specify the @quantity attribute. In N121, the readable inscription does not appear to miss any words, but some text has evidently been lost before the first readable word. The missing text is encoded with the ‘indeterminate’ value:
<gap unit="indeterminate"/>
<choice>
<me:facs>ᚼ<unclear reason="damage">*</unclear>ᛚ
ᚢ<unclear reason="damage">*</unclear>ᚱᚦᚱ</me:facs>
<me:dipl>h<supplied reason="restoration">a</supplied>l
u<supplied reason="restoration">a</supplied>rþr</me:dipl>
<me:norm>H<supplied reason="restoration">a</supplied>ll
v<supplied reason="restoration">a</supplied>rðr</me:norm>
</choice>
</w>
<w>
<choice>
<me:facs>krenske</me:facs>
<me:dipl>krenske</me:dipl>
<me:norm>grenski</me:norm>
</choice>
</w>
<w>
<choice>
<me:facs>ᚱᛅᛁᛌᛐ</me:facs>
<me:dipl>ræist</me:dipl>
<me:norm>reist</me:norm>
</choice>
</w>In other cases, perhaps where only a small part is missing, the editor might like to try and restore the lost text. As in the previous example, the <gap/> element will be used on the facsimile level while the diplomatic and normalised levels offer the restored text in a <supplied> element. In N 63, a runestone from Granavollen, the top of the stone is damaged, but there are good reasons to believe that only a few runes have been lost, probably only ᛆᚠ af. The relevant part of the inscription would be encoded like this:
<w>
<choice>
<me:facs>ᚱᛁᛋᚦᛐᚢ</me:facs>
<me:dipl>risþtu</me:dipl>
<me:norm>reistu</me:norm>
</choice>
</w>
<w>
<choice>
<me:facs><gap quantity="2" unit="char"/>ᛐᛁᚱ</me:facs>
<me:dipl><supplied reason="restoration">af</supplied>tir</me:dipl>
<me:norm><supplied reason="restoration">ef</supplied>tir</me:norm>
</choice>
</w>
<w>
<choice>
<me:facs>ᛆᚢᚠᛆ</me:facs>
<me:dipl>aufa</me:dipl>
<me:norm>Aufa</me:norm>
</choice>
</w>Finally, in some cases the lost text may begin (or end) in a single word and continue in one or more other words. In these cases, one has to use more one <gap/> element for each presumed word. In N564, there is a gap of approximately six characters, which probably extends over two words. The first rune of the first word is readable as ᛁ i and the second possibly as ᛆ a, while the last rune of the second word possibly may be read as ᛚ l. From the context, there are compelling reasons to assume that the two words are “iarl fell”, leading to this encoding:
<w>
<choice>
<me:facs>ᛁ<unclear reason="damage">ᛆ</unclear><gap quantity="2" unit="char"/></me:facs>
<me:dipl>i<supplied reason="restoration">arl</supplied></me:dipl>
<me:norm>j<supplied reason="restoration">arl</supplied></me:norm>
</choice>
</w>
<w>
<choice>
<me:facs><gap quantity="3" unit="char"/><unclear reason="damage">ᛚ</unclear></me:facs>
<me:dipl><supplied reason="restoration">fell</supplied></me:dipl>
<me:norm><supplied reason="restoration">fell</supplied></me:norm>
</choice>
</w>As for the display of lost text, see ch. 8.2.2 and ch. 9.3.1.1 above.
18.3.13 Cipher runes
Cipher runes (“lønnruner” or “løynderuner”) are found in a number of Norwegian inscriptions, especially from Bryggen in Bergen. There are different types of cipher runes, but they are based on the same principle, i.e. first giving the number of the rune row (ǽtt), then then number of the rune within the row. The rows were usually counted from the bottom to the top, while the number of the rune usually was counted from left to right, as shown in ill. 18.15.

Ill. 18.15. The younger runes according to the rune rows and their position within the row. Illustration by the chapter editor.
The rune ᚱ r which was located in the third row (counting form the bottom) and being No. 5 in this row, might be recorded as branches on either side of a stave, 3 for the row and 5 for the position. In a stylished version this cipher rune can be rendered as 3|5. A solidus, /, is often used in this type of rendering, but due to the fact that the solidus is often taken to mean alternatives, we recommend using the vertical bar, which also has a greater resemblance with a rune stave.

Ill. 18.16. Inscription in which the final two words have been written in cipher runes. || N 493 (Bryggen in Bergen). Drawing by K. Jonas Nordby (2018, p. 343).
In the example from B 493, the last two words are written in cipher runes. We recommend encoding the cipher runes in the way exemplified above on the facsimile level, while they should be interpreted and transliterated on the diplomatic level. The normalised level follow the same rules as in other runic inscriptions:
<w>
<choice>
<me:facs>2|4 1|3 1|3 3|2</me:facs>
<me:dipl>allum</me:dipl>
<me:norm>ǫllum</me:norm>
</choice>
</w>
<w>
<choice>
<me:facs>2|1 3|2 2|1 2|4</me:facs>
<me:dipl>huha</me:dipl>
<me:norm>huga</me:norm>
</choice>
</w>It goes without saying that a good illustration, photo and drawing, is important for the documentation and understanding of inscriptions with cipher runes. For a broad overview, see the doctoral dissertation by K. Jonas Nordby, Lønnruner: Kryptografi i runeinnskrifter fra vikingtid og middelalder, University of Oslo, 2018.
In the latest version of the UNI Runes font (20 September 2023), there is a full set of generalised cipher runes, so that they can be displayed in a runic shape (a vertical bar with right-angle branches on either side) rather than by numbers.
18.4 Header
Due to the huge number of runic inscriptions and their overall brevity, we recommend a fairly simple header. Below, it has been exemplified with an inscription from Gausdal, reading (in normalised transliteration) Eilífr Elgr bar fiska í Rauðusjó “Eilífr Elk carried (i.e. released) fish into Rauðusjór”. The headers will in most respects be identical to the manuscript header discussed in ch. 14 and exemplified in app. E. However, the recommended header in this chapter will be considerably shorter.
18.4.1 Introduction
All runic inscriptions are examples of a single-text source, as exemplified in ch. 14.7 above. The header has four major parts:
| Elements | Contents |
|---|---|
| <fileDesc> | A file description |
| <encodingDesc> | An encoding description |
| <profileDesc> | A text profile |
| <revisionDesc> | A revision history |
This chapter will discuss the recommended amount of information for each of the four parts. The first of these, the file description is the largest of the four, so for practical reasons we will divide it into two subchapters, ch. 18.4.2 covering the title, editor, extent and publication of the runic inscription, and ch. 18.4.3 covering the contents of the runic inscription.
18.4.2 The file description: title, edition, extent and publication
The file description is a mandatory part of the header, cf. the TEI P5 Guidelines, ch. 2.2. We begin by discussing the meta-level information on the file, described in following four elements:
| Elements & attributes | Explanation |
|---|---|
| <titleStmt> | Information on the title, editor and other people who have been responsible for the edition. |
| <editionStmt> | A description of the edition (i.e. version), typically by means of a number. |
| <extent> | The size of the file, preferably specified in words. |
| <publicationStmt> | A statement of the publication, i.e. the publisher of the text, reference number, date of publication, and availability. |
18.4.2.1 Title statement
In the <titleStmt>, the <title> element gives the title of the document. The title is divided into three major parts, divided by colons:
- Standard reference to the inscription, for Norwegian inscriptions usually N + a number.
- Location of the inscription.
- States that the present text is a digital edition.
<title>N 58 † : Li, Gausdal, Innlandet : A digital edition</title>In addition to the inscriptions referred to with N + a number, there are separate series of A + a number (inscriptions from Oslo, Tønsberg, Trondheim and other places) and B + a number (inscriptions from Bryggen in Bergen). These numbers are used in the Runor database, in the case of the A and B series, prefaced by an N (for Norway), e.g. N A39 (an inscription from Tønsberg), N B118 (an inscription from Bryggen in Bergen), etc.
The cross mark means that the inscription is lost and only survives in records. In this case, it is the stone on which the runes were carved that is lost. This is not unusual.
In addition to the title, the <titleStmt> must also list the editor(s) and other contributors to the edition. We recommend that one or more people (or institutions) are identified as the main editor(s) of the text in the <editor> element. With respect to Norwegian runic inscription, the majority has been edited in the six volumes so far published of Norges Innskrifter med de yngre Runer (the seventh, on the Trondheim inscriptions, is due to appear soon). Unless the inscription is published from scratch as it were, we believe that it would be most correct to credit the editor of the NIyR volume as the initial editor, and then list other contributors in the subsequent <respStmt> elements.
The NIyR volumes have the following editors:
- Vol. 1–2: Magnus Olsen
- Vol. 3: Magnus Olsen and Aslak Liestøl (the latter from No. 217 Ålgård)
- Vol. 4–5: Magnus Olsen and Aslak Liestøl
- Vol. 6.1: Aslak Liestøl
- Vol. 6.2: Aslak Liestøl and Ingrid Sanness Johnsen
The N58 inscription, originally published in vol. 1 of NIyR, should thus be credited to Magnus Olsen:
<editor role="person">
<name>
<persName>
<forename>Magnus</forename>
<surname>Olsen</surname>
</persName>
<orgName type="affiliation">University of Oslo</orgName>
</name>
</editor>After having stated the editor(s) of the file, one or more <respStmt> elements should specify the main tasks behind the publication. The <respStmt> opens with a <resp> element stating the type of work and a <name> element stating who is responsible for the work, either a person or an institution. In the present example, the first <respStmt> would be the one specifying the contribution of the main editor(s). This could be supplemented by an assistant editor, if relevant:
<respStmt>
<resp>Publishing of the runic inscription in NIyR vol. 1, pp. 118–123</resp>
<name>
<persName>
<forename>Magnus</forename>
<surname>Olsen</surname>
</persName>
<orgName type="affiliation">University of Oslo</orgName>
</name>
</respStmt>In the case of a text which has been developed through several stages (possibly at more than one institution), the <editor> and the <respStmt> elements will by necessity be longer. This is typically the case for runic inscriptions, which may be credited to several institutions and people. This is the suggested full <titleStmt> for the N58 inscription:
<titleStmt>
<title>N58 † : Li, Austre Gausdal, Oppland : A digital edition</title>
<editor role="person">
<name>
<persName>
<forename>Magnus</forename>
<surname>Olsen</surname>
</persName>
<orgName type="affiliation">University of Oslo</orgName>
</name>
</editor>
<respStmt>
<resp>Publishing of the runic inscription in NIyR vol. 1, pp. 118–123</resp>
<name>
<persName>
<forename>Magnus</forename>
<surname>Olsen</surname>
</persName>
<orgName type="affiliation">University of Oslo</orgName>
</name>
</respStmt>
<respStmt>
<resp>Provision of the Runor database</resp>
<name>
<orgName type="affiliation">Swedish National Heritage Board
(Riksantikvarieämbetet)</orgName>
</name>
</respStmt>
<respStmt resp="annotation">
<resp>Digital rendering and annotation</resp>
<name>
<persName>
<forename>Your</forename>
<surname>Name</surname>
</persName>
<orgName type="affiliation">University of Bergen</orgName>
</name>
</respStmt>
<respStmt>
<resp>Project overview</resp>
<name>
<persName>
<forename>Odd</forename>
<forename>Einar</forename>
<surname>Haugen</surname>
</persName>
<orgName type="affiliation">University of Bergen</orgName>
</name>
</respStmt>
</titleStmt>18.4.2.2 Edition statement
The <editionStmt> should be used to specify whether the present text is a new or a revised edition of the digital text as described in the title statement above. Here, “edition” is to be understood as “version”. The version number should be given in the @n attribute with the usual number system, i.e. ‘1.0’, ‘1.0.1’, ‘1.1’, etc. The date of the version should be given in the format year-month-day in the @when attribute, e.g. ‘2020-01-12’.
A complete edition statement may be as simple as this:
<editionStmt>
<edition n="2.0">Version 2.0 <date when="2020-01-06">6 January 2020</date> </edition>
</editionStmt>18.4.2.3 Extent
The <extent> element specifies the size of the file. The exact number of words should be given in the @n attribute as well as in plain text within the element, e.g.:
<extent n="6">6 words</extent>In a Menota XML file, each word will be contained in a <w> element, so the number of words can simply be regarded as equal to the number of <w> elements in the file. On the whole, runic inscriptions are short, so the number of words will be correspondingly low.
Note that in a number of inscriptions, one or more lexical words have been written with no or only a few spaces. When normalised, the individual, lexical words should be placed within <w> elements, and it is the number of <w> elements that should be given here.
18.4.2.4 Publication statement
The <publisher> element specifies the body (publisher, archive) which has made the text available, e.g. the Medieval Nordic Text Archive (Menota).
The <idno> is a unique identification of the text. For Norwegian runic inscriptions, we suggest volume and page numbers in Norges Innskrifter med de yngre Runer (NIyR). If the inscription is unpublished in NIyR, a reference to its location in the Runic Archives hould be given instead.
The <date> specifies the first publication of the inscription. If there is just a single version of the publication, this date will be identical with the date stated in the <editionStmt> above, but if there are more than one version, the date in the <editionStmt> will be more recent. Also here, the date should be given in the format year-month-day in the @when attribute, e.g. ‘2020-01-12’
The <availability> element specifies the accessibility of the text. We recommend adding a @status attribute with one of the three values: ‘free’, ‘restricted’ or ‘unknown’ (cf. the TEI P5 Guidelines, ch. 2.2.5). Almost all texts in the Menota archive are now available under an open CC license, and this should be stated in a <license> element with link to the Creative Commons website. Details on the transferral of this license should be added in a <p> element.
A complete publication statement may thus look like this:
<publicationStmt>
<distributor>Medieval Nordic Text Archive</distributor>
<idno type="NIyR">I 118–123</idno>
<date when="2018-02-13">13 February 2018</date>
<availability status="free">
<licence target="http://creativecommons.org/licenses/by-sa/4.0/">CC-BY-SA 4.0</licence>
</availability>
</publicationStmt> 18.4.3 The file description: source, identification, contents, physical form and history
The next part of the file description to be discussed here is the <sourceDesc>, which describes the source material (cf. the TEI P5 Guidelines, ch. 2.2.7). It is a child of <fileDesc>, and in the case of a runic inscription, the source is the object carrying the transcribed inscription.
The very first element within the <sourceDesc> states whether there is a facsimile (photograph, drawing or the like) of the inscription, and if there is, the location of the facsimile. This is typically a brief statement:
<sourceDesc>
<bibl facs="yes">Drawing from the Runic Archives in Oslo.</bibl>
. . .
</publicationStmt> Next, the source is described in the <msDesc> element. This description needs not consist of more than the basic information necessary to identify the source, i.e. its location, both geographical and institutional, and its shelfmark or other identifying numbers or names.
Within <msDesc> the following five elements are available:
| Elements & attributes | Explanation |
|---|---|
| <msIdentifier> | Groups information that uniquely identifies the runic inscription, e.g. by geographical coordinates |
| <msContents> | Contains an itemised list of the intellectual content of the runic inscription, either as a series of paragraphs or as a series of structured manuscript items. |
| <physDesc> | Groups information concerning all physical aspects of the runic inscription, its material, size, format, script, decoration, marginalia etc. |
| <history> | Provides information on the history of the runic inscription, its origin, provenance and acquisition by its holding institution. |
| <additional> | Groups other information about the runic inscription, in particular, administrative information relating to its availability, custodial history, surrogates etc. |
We recommend that <msIdentifier>, <physDesc> and <history> elements are included in the header for a runic inscription, but the <msContents> and <additional> elements are facultative.
18.4.3.1 Inscription identifier
While the <msIdentifier> for a manuscript typically will be the archive or library where it is held today, we recommend that the identifier for a runic inscription is its original location. The location should be specified with reference to <country> using the @key attribute with values such as ‘NO’ for Norway, ‘SE’ for Sweden, and so on according to the ISO 3166-1 alpha 2 standard.
The <settlement> can be given with specific geographical coordinates, copied from the Runor database.
The <repository> states the present-day holding institution, if the inscription (or rather the object on which the inscription is located) has been moved from its original site. If it has been lost, the contents may simply be “lost”, perhaps with some additional information.
The <idno>> contains the standard reference to the inscription. This should be identical to the first part of the <title>, as specified above. In the case of the Gausdal inscription, it is N58.
The <msName> for a runic inscription can be given as the standard reference + the geographical location. For the Gausdal inscription, it will be N58 † : Li, Austre Gausdal, Oppland.
A <msIdentifier> for the Gausdal inscription may look like this:
<msIdentifier>
<country key="NO">Norway</country>
<settlement>61.2768, 10.1327 (lat, long)</settlement>
<repository>Lost in 1839</repository>
<idno>N58</idno>
<msName>N58 † : Li, Austre Gausdal, Oppland</msName>
</msIdentifier>18.4.3.2 Intellectual contents
A detailed description of an inscription’s intellectual contents can be specified in the <msContents> element, which is the next major sub-element of the <msDesc> element. This level of information can be useful for a complex codex, but it is rarely necessary for a runic inscription.
18.4.3.3 Physical descriptions
The next major element in the <msDesc> element is a physical description, <physDesc>. The first element within <physDesc> is <objectDesc>, which relates specifically to the text-bearing object and contains two further sub-elements, <supportDesc> and <layoutDesc>.
The element <supportDesc> can contain various aspects relating to the physical object, or carrier, on which the text is inscribed, such as <support>, describing whether the inscription is on stone, wood, bone, etc., <extent> detailing number of lines or faces, and <condition>, for a description of the current physical state of the object.
We recommend a very simple <physDesc>, only specifying the material and perhaps the condition:
<objectDesc form="stone">
<supportDesc>
<support> <p><material>Stone</material>.</p></support>
<condition>Lost</condition>
</supportDesc>
</objectDesc> The second group of elements within a structured physical description concerns aspects of the writing, illumination or the like, including additions made in later hands. This may be useful for runic inscriptions on picture stones or inscriptions which are part of an ornament, but for the majority of simple runic inscriptions, it can be left out.
18.4.3.4 The history of the object and its inscription
The <history> element contains information on the history of the inscription. Available within it are three sub-elements: <origin>, for information on when the inscription was made; <provenance>, in which any evidence of ownership and use is provided; and <acquisition>, which describes when and how the object was acquired by its current owner or holding institution. Each of these elements may contain one or more paragraphs which may contain more specialised elements.
For the encoding of runic inscriptions, we recommend that the <origin> is specified with a date in the <origDate> element, using dating by year or (in almost all cases) by period in years.
The encoding can be as simple as this:
<history>
<origin>
<origDate notBefore="1050" notAfter="1100">c. 1050-1100</origDate>
</origin>
</history> 18.4.4 The encoding description
The <encodingDesc> documents the relationship between the digital edition and the source it is based upon. It is an optional part of the header, but we recommend that it contains information on the standard of encoding and level of quality. It should have two sub-elements: a <projectDesc> and an <editorialDecl>.
The <projectDesc> can state the standard of the encoding in prose, e.g. “This text has been encoded according to the standard set out in The Menota Handbook, version 3.0, at https://menota.org/handbook.xml”. If it was part of a project, this can be stated here, e.g. “This inscription has been encoded as part of a course in Old Norse philology held at the University of Bergen in the spring term of 2021.
The <editorialDecl> uses the <correction> element with the @status attribute to specify the level of quality control. Attribute values (according to TEI) are ‘high’, ‘medium’, ‘low’ and ‘unknown’. The TEI P5 Guidelines, ch. 2.3.3 offer these definitions for the possible values:
- high: the text has been thoroughly checked and proofread
- medium: the text has been checked at least once
- low: the text has not been checked
- unknown: the correction status of the text is unknown
Once the @status attribute is given a value, the <correction> element may be empty. However, if desired, further specification can be given in prose within a <p> element.
Next within the <editorialDecl> element, a <normalization> element with a Menota-specific @me:level attribute is used to specify the level on which the text is encoded. The prototypical levels are ‘facs’, ‘dipl’ and ‘norm’, but other levels can also be used in the transcription, e.g. a ‘pal’ level for a very close paleographical transcription. Also here, a description in prose may be added in a <p> element. Note that more than one level may be specified, in which case they should be separated by whitespace:
<editorialDecl>
<normalization me:level="facs dipl norm">
<p>This inscription has been encoded on three levels:
facsimile, diplomatic and normalised.</p>
</normalization>
</editorialDecl>
Finally within the <editorialDecl> element, an <interpretation> element is used to specify the amount of lexical and grammatical information in the encoded text. We suggest two attributes, @me:lemmatized and @me:morphAnalyzed, both with the values: ‘completely’, ‘partly’ and ‘none’. An additional description in prose may be added in a <p> element. A lemmatised text will have lemmata (i.e. dictionary entries) added in the @lemma attribute of the <w> element, while a morphologically analysed text will have grammatical forms specified in the @me:msa attribute of the same element. See ch. 5.3 above for a general overview and ch. 11 above for details on this lexical and morphological encoding.
A complete <encodingDesc> may look like this:
<encodingDesc>
<projectDesc>
<p>This encoding follows the standard set out in <title>The Menota Handbook</title>
(version 3.0), at <ref target="http://www.menota.org/handbook">
http://www.menota.org/handbook</ref> as of <date>2019-12-12</date>.</p>
<p>The inscription has been encoded as part of a course in Old Norse philology held
at the University of Bergen in the spring term of 2021.</p>
</projectDesc>
<editorialDecl>
<correction status="high">
<p>This inscription has been transcribed from the source as it has been published in
the Runor database.</p>
</correction>
<normalization me:level="facs dipl norm">
<p>This inscription has been encoded on all three focal levels: facsimile,
diplomatic and normalised.</p>
</normalization>
<interpretation me:lemmatized="completely" me:morphAnalyzed="completely">
<p>The whole inscription has been lemmatised and morphologically analysed.</p>
</interpretation>
</editorialDecl>
</encodingDesc> 18.4.5 The profile description
The <profileDesc> is an optional part of the header, but we strongly recommend that the language(s) used in the source are listed here within the element <langUsage>. This element contains one or more <language> elements with an @ident attribute each. The value of @ident should be a three-letter code, where possible based on the international standard ISO 639-2.
A <profileDesc> may look like this:
<profileDesc>
<langUsage>
<language ident="nor">Norwegian</language>
<language ident="lat">Latin</language>
</langUsage>
</profileDesc>18.4.6 The revision description
Even if this is an optional part of the header, it is essential that all changes to the file are recorded. Each change is described within a separate <change> element. Within it, the <date> is given first, then the <name> of the revisor (preferably with affiliation), and, finally, a description in prose of the actual change.
A short series of <change> elements may look like this:
<revisionDesc>
<change> <date>2020-01-10</date> <name> <persName>Odd Einar Haugen</persName>
<orgName type="affiliation">University of Bergen</orgName> </name>:
Minor changes to the transcription and additions to the header.
</change>
<change> <date>2020-01-07</date> <name> <persName>Robert K. Paulsen</persName>
<orgName type="affiliation">University of Bergen</orgName> </name>:
Minor changes to the transcription after a proofreading.
</change>
</revisionDesc>18.5 Text: front, body and back
We recommend that each edition of a runic inscription has a full <text> element, containing an introductory <front> element, a <body> element with the actual inscription, and a <back> element with translation(s), image(s) and other accompanying material. The structure is as outlined in ch. 3.2 above:
| Elements | Contents |
|---|---|
| <text> | The text itself begins here, |
| <front> . . . </front> | any front matter goes here, |
| <body> . . . </body> | the main body of the text goes here, |
| <back> . . . </back> | any back matter goes here, |
| </text> | and the text ends here. |
18.5.1 Front
The front matter should contain a brief identification of the inscription followed by a brief description, usually in a modern language. Both are placed in a <div> element with a @type attribute, the identification in a <head> element and the description in one or more <p> elements.
| Elements & attributes | Explanation |
|---|---|
| <div> | Contains the contents of the <front> element |
| @type | Indicates what type of section it is. |
| ‘abstracts’ | An abstract of the inscription, including necessary identification |
| <head> | A descriptive title of the inscription, usually organised into (a) Signum, (b) Place, (c) Date, (d) Edition |
| <p> | A brief description of the inscription |
The <front> element for the N58 inscription might look like this:
<div type="abstracts"
<head>
<hi rend="bold">Nr.</hi>: N58.
<hi rend="bold">Stad</hi>: Li, Gausdal, Innlandet fylke.
<hi rend="bold">Datering</hi>: ca. 1050–1100
<hi rend="bold">Utgåve</hi>: NIyR I: 118–123
</head>
<p>Denne bautasteinen frå Li i Gausdal har ei innskrift som dokumenterer fiskerettar
i Rausjøen – enno i dag ligg dei til Li gard i Gausdal. I 1839 vart steinen brukt til grunnmur
i eit fjøs på garden, og har seinare ikkje vore attfunnen. Men innskrifta vart avteikna fleire
gonger, seinast i 1833 av student Chr. C.A. Lange, seinare riksantikvar. Jf. NIyR I: 118.
</div>It would require at least one sentence to give a description of the inscription, but preferably not more than, say, five sentences.
18.5.2 Body
This is the actual text of the source. As a rule, the inscription should be rendered in runic characters on the <me:facs> level, in a transliteration to the Latin alphabet on the <me:dipl> level, and finally in normalised orthography on the <me:norm> level.
The three levels are placed within a <choice> element, and this in turn within a <w> element. The latter will be the location for a morphological annotation of the word, using the @lemma and @me:msa attributes.
Since runic inscriptions may be written in several languages, particularly Norwegian and Latin, we recommend that the language is specified. This can be done as an attribute to the <body> element, like this example of an inscription written in Norwegian:
<body xml:lang="nor">If the inscription contains one or more words in another language, e.g. Latin, these words (or divisions) can be singled out by the same type of attribute:
<w xml:lang="lat">Anno</w>
<w xml:lang="lat">Domini</w>Note that the language codes used here must be defined in the <profileDesc> of the header, cf. ch. 18.4.5 above.
On the facsimile level, runes may be encoded by (a) runic characters, (b) character entities or (c) Unicode codepoints. In the example below, runic characters are used (which may not display correctly in all browsers):
<w lemma="Eilífr" me:msa="xNP">
<choice>
<me:facs>ᛆᛁᛚᛁᚠᚱ</me:facs>
<me:dipl>ailifr</me:dipl>
<me:norm>Eilífr</me:norm>
</choice>
</w>
<w lemma="elgr" me:msa="xNC">
<choice>
<me:facs>ᛆᛚᚴᚱ</me:facs>
<me:dipl>alkr</me:dipl>
<me:norm>elgr</me:norm>
</choice>
</w>In this example, the lemma has been added and the word class (part of speech), but not the full grammatical form.
Alternatively, character entities might be used, referring to the list in ch. 18.6.3 below:
<w lemma="Eilífr" me:msa="xNP">
<choice>
<me:facs>&aYG;&iGE;&lGE;&iGE;&fGE;&rGE;</me:facs>
<me:dipl>ailifr</me:dipl>
<me:norm>Eilífr</me:norm>
</choice>
</w>Or, Unicode codepoints, also referring to the list in ch. 18.6.3 below:
<w lemma="Eilífr" me:msa="xNP">
<choice>
<me:facs>ᛆᛁᛚᛁᚠᚱ</me:facs>
<me:dipl>ailifr</me:dipl>
<me:norm>Eilífr</me:norm>
</choice>
</w>Character entitites and Unicode codepoints both start with an ampersand, &, and end with a semicolon, ;. Between these delimiters, character entries always begin with a letter, and are case sensitive. Codepoints are prefixed by a number sign, #, followed either by digits only, or the lowercase letter x preceding hexadecimal digits. The latter are not case sensitive.
Character entities can be used for all runes, whether in the official Unicode Runic block or in the Private Use Area, while Unicode codepoints should never be used for characters in the Private Use Area. Here, character entities are essential.
18.5.3 Back
The back matter contains additional information on the inscription. As a minimum, we recommend a translation (into English and/or a modern Nordic language). There is also ample room for comments, illustrations (photos and/or drawings), links and possibly a responsibility statement. Each section is given within a <div> element with appropriate attributes and values.
| Elements & attributes | Explanation |
|---|---|
| <div> | Contains a separate section of the back matters. |
| @type | Indicates what type of section it is. |
| ‘translation’ | Translation of the inscripton, preferably on the literal side. The encoder is encouraged to offer two translations, one into English and another into a modern Nordic language. |
| ‘comment’ | Any comments on the inscription, whether of its transcription, transliteration, translation, contents or general background. |
| ‘illustration’ | Photos and/or drawings of the inscription, supplied by information on the producer (photographer, drawer) and the copyright licence. |
| ‘links’ | References to primary and secondary literature on the inscription, including web pages |
| ‘responsibility’ | A statement about who is responsible for the various parts of the file. |
Translations into English will be found in the Runor database, while a translation into a Modern Nordic language can be up to the encoder, unless an existing translation is preferable. In the latter case, remember to state the name of the translator. This counts as a quote, so it is not necessary to ask for permission.
Illustrations are hugely helpful, so try to add one or more, whether photographs, drawings (‘avteikning’) or both. Ensure that you are allowed to publish the illustration(s), and remember to specify the licence for the permission.
The full <back> element of the N58 inscription might look like this (slightly simplified here):
<back>
<div type="translation" xml:lang="nor">
<head>Omsetjing til norsk</head>
<p>Eiliv Elg sette fiskar i Raudsjøen.</p>
</div>
<div type="translation" xml:lang="eng">
<head>Omsetjing til engelsk (etter innførselen i SamNord)</head>.
<p>Eilífr Elk carried (ie. released) fish into Rauðusjór.</p>
</div>
<div type="comment" xml:lang="nor">
<head>Kommentar</head>
<p>Som nemnt ovanfor har innskrifta vore avteikna tre gonger, først av Gerhard Schøning
i 1775, deretter av M.F. Arendt i 1805 og endeleg i 1833 av Chr. C.A. Lange. Dei tre
teikningane gjev ikkje att runene heilt likt. Det er verdt å merke seg at i avteikningna
til Lange, som er vist nedanfor, er det andre ordet attgjeve som ᛁᛚᚴᚱ
<hi rend="bold">ilkr</hi> og det tredje som ᛒᛁᚱ <hi rend="bold">bir</hi>, men
på grunnlag av dei to andre avteikningane er desse orda tolka som ᛆᛚᚴᚱ
<hi rend="bold">alkr</hi> og ᛒᛆᚱ <hi rend="bold">bar</hi>.
Jf. NIyR I: 119–121.</p>
<p>Det skal tidlegare ha vore aure (ørret) i Raudsjøen, men i nyare tid har det vore
sett ut gjedde: <ref target="https://no.wikipedia.org/wiki/Raudsjøen"
type="external">Raudsjøen</ref></p>
</div>
<div type="illustration">
<head>Illustrasjonar</head>
<figure><graphic url="N58-A.jpg"/></figure>
<caption>Avteikning av N 58 ved Chr.A. Lange (1833). Frå Runearkivet, Kulturhistorisk
museum, Universitetet i Oslo. Lisens: CC-BY-SA 4.0.</caption>
<figure><graphic url="N58-B.jpg"/></figure>
<caption>Avteikning av N 58 ved Gerhard Shøning (1775). Frå Runearkivet, Kulturhistorisk
museum, Universitetet i Oslo. Lisens: CC-BY-SA 4.0.</caption>
<figure><graphic url="N58-C.jpg"/></figure>
<caption>Avteikning av N 58 ved M.F. Arendt (1805). Frå Runearkivet, Kulturhistorisk
museum, Universitetet i Oslo. Lisens: CC-BY-SA 4.0.</caption>
</div>
<div type="links" xml:lang="nor">
<head>Kjelder</head>
<bibl>NIyR = <title>Norges innskrifter med de yngre runer</title>. Bd. 1. Utg. Magnus
Olsen. Oslo: Kjeldeskriftfondet, 1941.</bibl>
<bibl>“Raudsjøen.” Artikkel i den norske <title>Wikipedia</title>,
<ref target="https://no.wikipedia.org/wiki/Raudsjøen" type="external">
https://no.wikipedia.org/wiki/Raudsjøen</ref>. Lesen 26. august 2021.</bibl>
<bibl>SamNord = Samnordisk runetekstdatabase. Utvikla ved Uppsala universitet sidan
1980-talet og i 2020 publisert på nettsidene til det svenske Riksantikvarieämbetet,
<ref target="https://www.raa.se/hitta-information/runor/" type="external">
Om söktjänsten Runor</ref>.</bibl>
</div>
<div type="responsibility">
<head>Redaktør for denne innførselen</head>
<p>Odd Einar Haugen (Universitetet i Bergen, 2021)</p>
<p>Innførselen byggjer på publiserte ressursar, særleg NIyR og den Samnordiske
runetekstdatabasen. Redaktøren er ansvarleg for kodinga av innførselen i XML,
presentasjonen av innskrifta, kodinga av innskrifta på tre nivå, morfologisk annotasjon
og eventuelle kommentarar utover det som er å finne i dei publiserte kjeldene.</p>Since N58 has been lost, we have to rely on the few drawings of the inscription. For most inscriptions, however, there are one or more photos available. If possible, a drawing should be added to any photo, since this can help greatly in dechiffering the runes in a photo.
18.6 Typology and naming of runic characters
For this handbook, we suggest that runic characters can be divided into six partly overlapping classes. Some runic characters, such as the ᛁ rune 16CI, are used in almost all classes, others are present in several classes, such as the ᚴ rune 16B4, while some are known only in a single class, like many of the Medieval runes, for example the ᚵ rune 16B5.
The following classes are recognised in this chapter:
| Class | Explanation |
|---|---|
| GE | Runic characters used in all or almost all classes, having bascially the same sound value throughout the period. |
| OR | The older runic alphabet. |
| AF | Anglo-Saxon and Frisian runes. Used in Britain and Frisia, developed from the older runic alphabet. |
| YG | The younger runic alphabet, containing 16 runes. Some of the younger runes have two commonly recognised variants, the long-branch runes (YGL) and the short-twig runes (YGS). |
| SL | The staveless runes, which are based on the younger runic alphabet, but which have a very different graphical form. |
| MD | Medieval runes. Additions to the younger runes, typically modified by dots, branch position or branch length. |
| BR | Bind-runes. Ligatures of two (or in some cases more) runes. |
18.6.1 The Unicode selection
Runes were introduced in v. 3.0 of the Unicode Standard in 1999. The Unicode selection covers the major runic forms across the whole period, c. 200–1500, and in many, perhaps a majority of cases, they will suffice for a suitable representation of runic inscriptions. Originally, the runic chart contained 81 runes, 16A0–16F0. In v. 7.0, 8 more runes were added, 16F1–16F8. These are runes introduced by the author J.R.R. Tolkien for the writing of Modern English, and cryptogrammic letters used on Franks casket. These runes are not included below.
Class A: General runes
The seven runes in this class are found almost unchanged in all classes (although simplified in the staveless type) and they have more or less the same sound value across the whole period of runic writing. The ᚱ, ᛁ and ᛒ runes have identical shapes to Latin characters, the ᚠ rune if one accepts that the branches may be diagonal rather than horisontal, the ᛚ rune under the same condition and if one accepts that it has been turned upside-down. The ᚦ rune is typologically not far from the Latin D character, and even if the ᚦ rune denotes a dental fricative and the D character a dental plosive, they are both obstruents.
Spurkland (2001: 16–17) offers a somewhat different perspective on the relationship between Latin character shapes and runic ones. The perspective in this chapter is simply to identify runes which have been used throughout the whole period with a consistent sound value. For example, the ᚺ rune was most likeley based on the Latin H character, but it was changed into ᚼ in the younger runic alphabet, so it is not a candidate for a general rune. Actually, the new ᚼ rune was in some cases simplified to ᚽ, making difference even more pronounced.
It could be argued that the ᛒ rune is not truly general, since a common variant of this rune in the short-twig version of the younger runes looks quite different, ᛓ. However, since we are looking upon the younger runes as a single class, the ᛓ rune will be a variant of the general rune ᛒ. The latter rune therefore retains its generality.
The concept of “general runes” has been introduced in this chapter by the author.
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᚠ | f | fGE | 16A0 | GENERAL RUNE F |
| ᚢ | u | uGE | 16A2 | GENERAL RUNE U |
| ᚦ | þ | thGE | 16A6 | GENERAL RUNE THORN |
| ᚱ | r | rGE | 16B1 | GENERAL RUNE R |
| ᛁ | i | iGE | 16C1 | GENERAL RUNE I |
| ᛒ | b | bGE | 16D2 | GENERAL RUNE B |
| ᛚ | l | lGE | 16DA | GENERAL RUNE L |
Class B: Older runes
The older runes comprises 24 characters, of which 7 have been listed among the general runes above. Here, all 24 have been listed according to the traditional groups of eight runes. In other words, this is truly a ᚠᚢᚦᚨᚱᚲ fuþark.
There is some variation as to the sequence of the runes. In some standardised, “handbook” rune rows, the ᛇ and ᛈ runes have switched places, and the same goes for the two final runes, ᛞ and ᛟ. There is also some variation with respect to the shape of the runes, e.g. that the ᛇ rune may be shown as . The sound value of the latter rune, ᛇ, is not fully understood. It has been transliterated in several ways by runologists, e.g. as æ (Barnes 2012: 4), ë (Seim 2013: 138) and ï (Düwel 2001: 8).
As for the ᛉ rune, some runologists transliterate this as z (in line with the presumed Ancient Germanic sound), others as ʀ; Düwel (2001: 8) offers both, z/ʀ. We have decided on z, hence the character entity &zOR;. This way, it is kept distinct from the ordinary r which has the character entity &rOR;. One should bear in mind that the descriptive names to some extent are arbitrary.
The older runes are also known as the common Germanic runes or the elder futhark.
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᚠ | f | fGE | 16A0 | GENERAL RUNE F |
| ᚢ | u | uGE | 16A2 | GENERAL RUNE U |
| ᚦ | þ | thGE | 16A6 | GENERAL RUNE THORN |
| ᚨ | a | aOR | 16A8 | OLDER RUNE A |
| ᚱ | r | rGE | 16B1 | GENERAL RUNE R |
| ᚲ | k | kOR | 16B2 | OLDER RUNE K |
| ᚷ | g | gOR | 16B7 | OLDER RUNE G |
| ᚹ | w | wOR | 16B9 | OLDER RUNE W |
| ᚺ | h | hOR | 16BA | OLDER RUNE H |
| ᚾ | n | nOR | 16BE | OLDER RUNE N |
| ᛁ | i | iGE | 16C1 | GENERAL RUNE I |
| ᛃ | j | jOR | 16C3 | OLDER RUNE J |
| ᛇ | ë | iwazOR | 16C7 | OLDER RUNE IWAZ |
| ᛈ | p | pOR | 16C8 | OLDER RUNE P |
| ᛉ | ʀ | zOR | 16C9 | OLDER RUNE Z |
| ᛊ | s | sOR | 16CA | OLDER RUNE S |
| ᛏ | t | tOR | 16CF | OLDER RUNE T |
| ᛒ | b | bGE | 16D2 | GENERAL RUNE B |
| ᛖ | e | eOR | 16D6 | OLDER RUNE E |
| ᛗ | m | mOR | 16D7 | OLDER RUNE M |
| ᛚ | l | lGE | 16DA | GENERAL RUNE L |
| ᛜ | ŋ | ngOR | 16DC | OLDER RUNE NG |
| ᛞ | d | dOR | 16DE | OLDER RUNE D |
| ᛟ | o | oOR | 16DF | OLDER RUNE O |
Class C: Anglo-Saxon and Frisian runes
These runes are often simply referred to as Anglo-Saxon runes, but since there are earlier attestations of them from Frisia (i.e. Friesland), we have classified them as Anglo-Frisian. It is clear from the selection of runes that the inventory is based on the older runes, but there are several additions, too. In the list below, the 28 first runes are given in the sequence found in Barnes (2012: 37), while the five last runes are less common, and discussed by Barnes (2012: 36–41).
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᚠ | f | fGE | 16A0 | GENERAL RUNE F |
| ᚢ | u | uGE | 16A2 | GENERAL RUNE U |
| ᚦ | þ | thGE | 16A6 | GENERAL RUNE THORN |
| ᚩ | o | oAF | 16A9 | ANGLO-FRISIAN RUNE O |
| ᚱ | r | rGE | 16B1 | GENERAL RUNE R |
| ᚳ | c | cAF | 16B3 | ANGLO-FRISIAN RUNE C |
| ᚷ | g | gOR | 16B7 | OLDER RUNE G |
| ᚸ | g | gAF | 16B8 | ANGLO-FRISIAN RUNE G |
| ᚻ | h | hAF | 16BB | ANGLO-FRISIAN RUNE H |
| ᚺ | h | hOR | 16BA | OLDER RUNE H |
| ᛁ | i | iGE | 16C1 | GENERAL RUNE I |
| ᛄ | j | jAF | 16C4 | ANGLO-FRISIAN RUNE J |
| ᛇ | ë | iwazOR | 16C7 | OLDER RUNE IWAZ |
| ᛈ | p | pOR | 16C8 | OLDER RUNE P |
| ᛉ | x | xAF | 16C9 | ANGLO-FRISIAN RUNE X |
| ᛋ | s | sAF | 16CB | ANGLO-FRISIAN RUNE S |
| ᛏ | t | tOR | 16CF | OLDER RUNE T |
| ᛒ | b | bGE | 16D2 | GENERAL RUNE B |
| ᛖ | e | eOR | 16D6 | OLDER RUNE E |
| ᛗ | m | mOR | 16D7 | OLDER RUNE M |
| ᛚ | l | lGE | 16DA | GENERAL RUNE L |
| ᛝ | ŋ | ngAF | 16DD | ANGLO-FRISIAN RUNE NG |
| ᛞ | d | dOR | 16DE | OLDER RUNE D |
| ᛟ | o | oOR | 16DF | OLDER RUNE O |
| ᚪ | a | aAF | 16AA | ANGLO-FRISIAN RUNE A |
| ᚫ | æ | aeAF | 16AB | ANGLO-FRISIAN RUNE AESC |
| ᚣ | y | yAF | 16A3 | ANGLO-FRISIAN RUNE Y |
| ᛠ | ea | eaAF | 16E0 | ANGLO-FRISIAN RUNE EAR |
| ᛡ | j | ioAF | 16E1 | ANGLO-FRISIAN RUNE IOR |
| ᛢ | q | qAF | 16E2 | ANGLO-FRISIAN RUNE CWEORTH |
| ᛣ | k | kAF | 16E3 | ANGLO-FRISIAN RUNE CALC |
| ᛤ | k’ | kjAF | 16E4 | ANGLO-FRISIAN RUNE CEALC |
| ᛥ | st | stAF | 16E5 | ANGLO-FRISIAN RUNE STAN |
Class D: Younger runes
The introduction of the younger runic alphabet is commonly dated to the 8th century, maybe as early as c. 700. While the older runic alphabet had 24 runes, the younger alphabet was reduced to only 16 runes. Unlike the Anglo-Frisian runes, which contained a number of additional runes, the younger runic alphabet does not contain any completely new runes, but many of the older runes were re-designed, such as the n rune ᚾ changing into ᚿ and the t rune ᛏ becoming ᛐ. Other runes received a new usage, such as the ᚼ rune, which originally was an h rune, was now taken into use for the vowel a. While some of the younger runes, e.g. ᚴ k, is common to most versions of the younger runes, there is a distinction between the long-branch runes, “YGL”, commonly used in Denmark, and the short-twig runes, “YGS”, commonly used in Sweden and Norway. It should be emphasised that there is a high degree of variation of the runic forms, chronologically and regionally throughout the whole period. In the table below, typical forms have been used to illustrate what the runes looked like.
Almost all “handbook” rows of the younger runic alphabet agree on the number and sequence of the runes. In transliterated form, this is:
f u þ ã r k
h n i a s
t b m l ʀ
There is some variation with respect to the 4th rune, which is also transliterated as ą, and due to later development, as o. At this stage, the f u þ ã r k had become a f u þ o r k.
The table below has more than 16 runes, but this is a consequence of the fact that several of the runes had so different shapes that this must be reflected in their encoding and display. As with the previous classes, all codepoints are present in the official Unicode chart, 16A0–16E7.
The change from the older 24 characters runic alphabet to the new 16 characters alphabet has puzzled runologists, and there is as yet no commonly accepted explanation. For a fine and concise, but demanding, discussion, see Barnes (2012: 54–63).
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᚠ | f | fGE | 16A0 | GENERAL RUNE F |
| ᚢ | u | uGE | 16A2 | GENERAL RUNE U |
| ᚦ | þ | thGE | 16A6 | GENERAL RUNE THORN |
| ᚬ | ã | anYGL | 16AC | YOUNGER LONG-BRANCH RUNE NASAL A |
| ᚭ | ã | anYGS | 16AD | YOUNGER SHORT-TWIG RUNE NASAL A |
| ᚮ | o | oYG | 16AE | YOUNGER RUNE O |
| ᚱ | r | rGE | 16B1 | GENERAL RUNE R |
| ᚴ | k | kYG | 16B4 | YOUNGER RUNE K |
| ᚺ | ʜ | hOR | 16BA | OLDER RUNE H |
| ᚼ | h | hYGL | 16BC | YOUNGER LONG-BRANCH RUNE H |
| ᚽ | h | hYGS | 16BD | YOUNGER SHORT-TWIG RUNE H |
| ᚿ | n | nYG | 16BF | YOUNGER RUNE N |
| ᛁ | i | iGE | 16C1 | GENERAL RUNE I |
| ᚼ | ᴀ | aYGearly | 16BC | YOUNGER RUNE EARLY A |
| ᛆ | a | aYG | 16C6 | YOUNGER RUNE A |
| ᛋ | s | sYGL | 16CB | YOUNGER RUNE LONG-BRANCH S |
| ᛌ | s | sYGS | 16CC | YOUNGER RUNE SHORT-TWIG S |
| ᛏ | t | tOR | 16CF | OLDER RUNE T |
| ᛐ | t | tYG | 16D0 | YOUNGER RUNE T |
| ᛒ | b | bGE | 16D2 | GENERAL RUNE B |
| ᛓ | b | bYGS | 16D3 | YOUNGER RUNE SHORT-TWIG B |
| ᛗ | ᴍ | mOR | 16D7 | OLDER RUNE M |
| ᛘ | m | mYGL | 16D8 | YOUNGER RUNE LONG-BRANCH M |
| ᛙ | m | mYGS | 16D9 | YOUNGER RUNE SHORT-TWIG M |
| ᛚ | l | lGE | 16DA | GENERAL RUNE L |
| ᛦ | ʀ | RYGL | 16E6 | YOUNGER RUNE LONG-BRANCH VOICED R |
| ᛦ | y | yYG | 16E6 | YOUNGER RUNE Y |
| ᛧ | ʀ | RYGS | 16E7 | YOUNGER RUNE SHORT-TWIG VOICED R |
Note that the rune on codepoint 16E6 in the early period was used for the voiced ʀ, but that this rune during the Viking Age changed sound value to y (cf. Düwel 2001: 89 and 93). For this reason, we have two entities, RYGL and yYG, for the same glyph (i.e. runic form). This is perhaps less of a problem than one might think, at least from an encoding point of view. Whether one encodes a character as RYGL or yYG, the display will be by the same glyph, the one which is located at 16E6. On the other hand, when faced with the glyph ᛦ in an inscription, the encoder must decide whether it is an instance of ʀ or y and select the correct character entity. The context will usually tell which it is.
Class E: Staveless runes
The staveless runes are a maximally reduced form of the 16 younger runes in which the vertical stave has been removed, often leaving just a single short branch. There is in fact an almost complete 1 : 1 correspondence between the main form of the younger runic alphabet and the staveless subset. Note however, that there are two variant forms of the k rune, and that the ã rune has not been attested, but proposed as a mirrored version of the b rune.
Since the staveless runes uses three positions along the vertical dimension for contrastive purposes, they are often (as in the present font) drawn with a bottom and top line. These are not part of the runic character as such, but used for clarification. For example, the three runes have the original branch in high, mid and low position. The top and bottom lines underline this contrast of position.
| Character | Staveless | Translit. | Encoding | Code point | Comment |
|---|---|---|---|---|---|
| ᚠ | | f | fSL | F406 | STAVELESS RUNE F |
| ᚢ | | u | uSL | F414 | STAVELESS RUNE U |
| ᚦ | | þ | thSL | F428 | STAVELESS RUNE THORN |
| ᚬ | | ã | anSL | F434 | STAVELESS RUNE NASAL A |
| ᚱ | | r | rSL | F447 | STAVELESS RUNE R |
| ᚴ | | k | kSLst | F454 | STAVELESS RUNE K STRAIGHT FORM |
| ᚴ | | k | kSLcv | F455 | STAVELESS RUNE K CURVED FORM |
| ᚼ | | h | hSL | F46D | STAVELESS RUNE H |
| ᚿ | | n | nSL | F475 | STAVELESS RUNE N |
| ᛁ | | i | iSL | F478 | STAVELESS RUNE I |
| ᛆ | | a | aSL | F48F | STAVELESS RUNE A |
| ᛌ | | s | sSL | F4AC | STAVELESS RUNE S |
| ᛐ | | t | tSL | F4B9 | STAVELESS RUNE T |
| ᛓ | | b | bSL | F4CB | STAVELESS RUNE B |
| ᛘ | | m | mSL | F4E4 | STAVELESS RUNE M |
| ᛚ | | l | lSL | F4EB | STAVELESS RUNE L |
| ᛦ | | ʀ | RSL | F50C | STAVELESS RUNE VOICED R |
Class F: Medieval runes
The medieval runes represent a development of the younger runes from around 1000. The modifications are mostly in the form of added dots or a change of branch length or branch position. As early as the end of the 10th century, the three runes ᚢ, ᚴ and ᛁ were supplied with dots so as to represent ᚤ y, ᚵ g and ᛂ e. This development seems to have begun in Denmark and over the next centuries, additional modifications were made also in Sweden and Norway to the 16 characters younger runic alphabet. This resulted in what many regard as a new class of runes, the medieval runes, although some runologists might claim that the medieval runes should not be recognised as a class of its own, only as variants of and additions to the younger runic alphabet.
In general, the medieval runes are influenced by the Latin alphabet and the distinctions made in this. This influence seems to grow during the 13th and 14th centuries. In the list below, runes are given in alphabetical order rather than the fuþark order of the earlier runes. The opinion of runologists differ in this respect; we have chosen to follow Düwel (2001: 94) and Seim (2013: 175) in displaying the medieval runes in alphabetical order.
It should be remembered that there is a number of Latin inscriptions in the Nordic runic corpus. This explains why “non-Nordic” characters like c and q are included in the alphabet. It also explains the fact that there is a degree of syncretism in the runes offered below, so that e.g. the same rune, ᛋ, was used for c as well as for z.
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᛆ | a | aYG | 16C6 | YOUNGER RUNE A |
| ᛒ | b | bGE | 16D2 | GENERAL RUNE B |
| ᛋ | c | cMD | 16CB | MEDIEVAL RUNE C |
| ᛑ | d | dMD | 16D1 | MEDIEVAL RUNE D WITH DOT ON STAVE |
| | d | dMDdot | F4C2 | MEDIEVAL RUNE D WITH SEPARATE DOT |
| ᛂ | e | eMD | 16C2 | MEDIEVAL RUNE E |
| ᚠ | f | fGE | 16A0 | GENERAL RUNE F |
| ᚵ | g | gMD | 16B5 | MEDIEVAL RUNE G |
| ᚼ | h | hYGL | 16BC | YOUNGER LONG-BRANCH RUNE H |
| ᛁ | i | iGE | 16C1 | GENERAL RUNE I |
| ᚴ | k | kYG | 16B4 | YOUNGER RUNE K |
| ᚶ | ŋ | ngMD | 16B6 | MEDIEVAL RUNE ENG |
| ᛚ | l | lGE | 16DA | GENERAL RUNE L |
| ᛛ | l? | lMDdot | 16DB | MEDIEVAL RUNE L WITH DOT |
| ᛘ | m | mYGL | 16D8 | YOUNGER RUNE LONG-BRANCH M |
| ᚿ | n | nYG | 16BF | YOUNGER RUNE N |
| ᛀ | n? | nMDdot | 16C0 | MEDIEVAL RUNE DOTTED N |
| ᚮ | o | oYG | 16AE | YOUNGER RUNE O |
| ᛔ | p | pMD | 16D4 | MEDIEVAL RUNE P |
| ᛕ | p | pMDopen | 16D5 | MEDIEVAL RUNE OPEN P |
| ᛩ | q | qMD | 16E9 | MEDIEVAL RUNE Q |
| ᚱ | r | rGE | 16B1 | GENERAL RUNE R |
| ᛌ | s | sYGS | 16CC | YOUNGER RUNE SHORT-TWIG S |
| ᛍ | s | sYGSdot | 16CD | YOUNGER RUNE SHORT-TWIG S WITH DOT |
| ᛐ | t | tYG | 16D0 | YOUNGER RUNE T |
| ᚦ | þ | thGE | 16A6 | GENERAL RUNE THORN |
| ᚧ | ð | dhMD | 16A7 | MEDIEVAL RUNE ETH |
| ᚢ | u | uGE | 16A2 | GENERAL RUNE U |
| ᚡ | v | vMD | 16A1 | MEDIEVAL RUNE V |
| ᚥ | w | wMD | 16A5 | MEDIEVAL RUNE W |
| ᚼ | x | xMDhtyp | 16BC | MEDIEVAL RUNE H-TYPE X |
| ᛪ | x | xMDstyp | 16EA | MEDIEVAL RUNE S-TYPE X WITH STROKES |
| ᛦ | y | yYG | 16E6 | YOUNGER RUNE Y |
| ᚤ | y | yMD | 16A4 | MEDIEVAL RUNE DOTTED U |
| ᛋ | z | zMD | 16CB | MEDIEVAL RUNE Z |
| ᛎ | z | zMDsht | 16CE | MEDIEVAL RUNE SHORT Z |
| ᛅ | æ | aeMD | 16C5 | MEDIEVAL RUNE AE |
| ᚯ | ø | oeMD | 16AF | MEDIEVAL RUNE O SLASH |
| ᚰ | ǫ | oeMDsht | 16B0 | MEDIEVAL RUNE O SLASH SHORTENED |
| ᛨ | y | yMDisl | 16E8 | MEDIEVAL RUNE ICELANDIC Y |
Class G: Bind-runes
Bind-runes are ligatures of two (or more) runes, using a shared vertical part of each rune. The great majority of bind-runes are made up of two runes, and they are mostly from the younger runic alphabet. There are also examples of bind-runes made up of three or even four runes. The number of bind-runes in the whole runic corpus is alarmingly high, as demonstrated by Mindy MacLeod in her overview of bind-runes (2002). She has, for example, documented no less than 137 bind-runes in the corpus of medieval Norwegian inscriptions (2002: 217–223).
Bind-runes have typically been encoded and displayed as a sequence of the individual runes placed under an inverted breve, whether they are rendered in runic transcription, e.g. ᛆ, or in transliteration to the Latin alphabet, ar. There are good reasons to follow this convention, one of them being the general lack of font support.
On the other hand, there are reasons to look upon the bind-runes as characters of their own, in the same manner as the established ligatures in Latin script, such as ‘æ’ (a+e) and ‘œ’ (o+e). It will, however, require a font solution, and this is what the UNI Runes font now offers, although as a first step by a limited selection.
The table below contains all bind-runes in the two major Nordic runica manuscripta, AM 28 8vo (Codex Runicus) and SKB A 120 (often referred to as Mariaklagen or Maria’s lament). Most of the bind-runes in the table are found in a number of other runic inscriptions.
The character entities and descriptive names follow the standard set out above, which means that they can be fairly long. This should be seen as a reasonable price to pay for transparency in their naming. The entity names opens with ‘LIG’ to state that they are ligatures (bind-runes) and then list each component rune in the order of their transliteration. In the great majority of cases, this is also the order of the runic components, such as in ar where the a rune precedes the r rune. The descriptive names follow suit, but add a ‘PLUS’ between the components to make the sequence unequivocal.
The Menota entity list has been updated with the new character entities for bind-runes. See Appendix D.1.1 for details.
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| | af | LIGaYGfGEcv | F553 | LIGATED YOUNGER RUNE A PLUS GENERAL RUNE F WITH CURVED BRANCHES |
| | af | LIGaYGfGEst | F554 | LIGATED YOUNGER RUNE A PLUS GENERAL RUNE F WITH STRAIGHT BRANCHES |
| | al | LIGaYGlGE | F55B | LIGATED YOUNGER RUNE A PLUS GENERAL RUNE L |
| | ar | LIGaYGrGE | F564 | LIGATED YOUNGER RUNE A PLUS GENERAL RUNE R WITH CURVED BRANCHES |
| | aþ | LIGaYGthGEcv | F56D | LIGATED YOUNGER RUNE A PLUS GENERAL RUNE THORN WITH CURVED BRANCHES |
| | æuk | LIGaeMDuGEkYGcv | F572 | LIGATED MEDIEVAL RUNE AE PLUS GENERAL RUNE U PLUS YOUNGER RUNE K WITH CURVED BRANCHES |
| | eu | LIGeMDuGE | F603 | LIGATED MEDIEVAL RUNE E PLUS GENERAL RUNE U |
| | ok | LIGoYGkYGcv | F615 | LIGATED YOUNGER RUNE O PLUS YOUNGER RUNE K WITH CURVED BRANCHES |
| | ok | LIGoYGkYGst | F616 | LIGATED YOUNGER RUNE O PLUS YOUNGER RUNE K WITH STRAIGHT BRANCHES |
| | or | LIGoYGrGEcv | F61E | LIGATED YOUNGER RUNE O PLUS GENERAL RUNE R WITH CURVED BRANCHES |
| | ør | LIGoeMDrGEcv | F627 | LIGATED MEDIEVAL RUNE O SLASH PLUS GENERAL RUNE R WITH CURVED BRANCHES |
| | sk | LIGsYGLkYGcv | F628 | LIGATED YOUNGER RUNE LONG-BRANCH S PLUS YOUNGER RUNE K WITH CURVED BRANCHES |
| | tu | LIGtYGuGE | F630 | LIGATED YOUNGER RUNE T PLUS GENERAL RUNE U |
| | un | LIGuGEnYG | F635 | LIGATED GENERAL RUNE U PLUS YOUNGER RUNE N |
18.6.2 Additions assigned to the Private Use Area
There are a number of additional runic forms. Some of these will probably be recognised as runic characters in their own right, according to the strict Unicode criteria. A case in point would be the staveless runes, which are unique from a graphic point of view, even if the inventory closely corresponds with the standard row of the younger runes. Other runes should probably be regarded as variants of one of the runic characters in ch. 18.6.1 above, while a number of runes presented here fall somewhere between fully-fledged characters and mere variants. For practical reasons, we list them here for the simple reason that they are not in the official Unicode chart and thus have to be encoded in the Private Use Area. Some of them may migrate to an extended official chart in due course of time.
In the table below, runes are listed in the order they appear within the official Unicode code chart. The first line in each block is the official runic character, identified by the codepoint range 16A0–16F0. Then, one ore more variants follows with their codepoints in the Private Use Area and, most importantly in our context, a character entity [still under discussion]. Some of the runes in the official Unicode code chart have not been registered with any variant. Like any other runes, they may have been drawn with slightly different shapes in the primary sources. The lack of variants for these runes only means that no specific variants have been identified by the author of this chapter in the literature he has searched.
One major design feature has repercussions for the encoding in this table: straight vs. curved branches. In the available runic fonts, runes are rendered with two types of branches, as exemplified by the f rune, or ᚠ. This is not a distinctive feature from a phonological point of view, but it has a distinct influence on the display of runes in various fonts. The rationale behind the encoding below is that if the question of straight or curved branches does not matter for the encoder, one should simply use the standard encoding. In the case of the f rune, this will be 16A0 or the character entity &fGE;. The rune will then be displayed in the form selected in the font (decided by the font designer), and this may be either or ᚠ. Fonts seem to mix runes with straight and curved branches. If the encoder would like to have control of the specific shape, this can be attained by using either the character entity &fGEcv; or the character entity &fGEst;. It should be pointed out that using character entities is a suboptimal solution, but it does have the merit of operationality.
A final word of warning: While it is possible to have all of these runes displayed in a document by including the Private Use Area codepoints, one should never ever use these codepoints in an XML document for Menota. Any runes in the Private Use Area should always be encoded by character entities. These will be linked to the codepoints in the font by way of the Menota entity list. Runes in the offical Unicode chart, i.e. 16A0–16F0, can safely be entered as such, although also for these, one may use character entities.
Note: The table below is provisional. The character entities in the encoding column is still under discussion.
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᚠ | f | fGE | 16A0 | GENERAL RUNE F (BRANCH CURVATURE NOT SPECIFIED) |
| ᚠ | f | fGEcv | F407 | GENERAL RUNE F WITH CURVED BRANCHES |
| | f | fGEst | F400 | GENERAL RUNE F WITH STRAIGHT BRANCHES |
| | f | fGEfhst | F401 | GENERAL RUNE F WITH STRAIGHT BRANCHES FLIPPED HORISONTALLY |
| | f | fGEfvst | F402 | GENERAL RUNE F WITH STRAIGHT BRANCHES FLIPPED VERTICALLY |
| | f | fGEfhvst | F403 | GENERAL RUNE F WITH STRAIGHT BRANCHES FLIPPED HORISONTALLY AND VERTICALLY |
| | f | fGEst3br | F404 | GENERAL RUNE F WITH THREE STRAIGHT BRANCHES |
| | f | fGE2twupr | F405 | GENERAL RUNE F WITH TWO TWIGS UPWARDS TO THE RIGHT |
| | f | fSL | F406 | STAVELESS RUNE WITH FULL-LENGTH STAVE WITH UPPER DOT |
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᚡ | v | vMD | 16A1 | MEDIEVAL RUNE V (BRANCH CURVATURE NOT SPECIFIED) |
| ᚡ | v | vMDcv | 16A1 | MEDIEVAL RUNE V WITH CURVED BRANCHES |
| | v | vMDst | F40C | MEDIEVAL RUNE V WITH STRAIGHT BRANCHES |
| | v | vMDcvstr | F40E | MEDIEVAL RUNE V WITH CURVED BRANCHES AND STROKE |
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᚢ | u | uGE | 16A2 | GENERAL RUNE U |
| | u | uGEfh | F410 | GENERAL RUNE U FLIPPED HORISONTALLY |
| | u | uGEdg | F415 | GENERAL RUNE U WITH DIAGONAL BRANCH |
| | u | uGElowbr | F412 | GENERAL RUNE U WITH LOW BRANCH |
| | u | uGEdbldg | F413 | GENERAL RUNE U WITH DIAGONAL STAVE AND BRANCH |
| | u | uSL | F414 | STAVELESS RUNE U |
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᚣ | y | yAF | 16A3 | ANGLO-FRISIAN RUNE Y |
| | y | yAFdg | F418 | ANGLO-FRISIAN RUNE Y WITH DIAGONAL BRANCH |
| | y | yAFdblcv | F419 | ANGLO-FRISIAN RUNE Y WITH CURVED STAVE AND BRANCH |
| | y | yAFcros | F41A | ANGLO-FRISIAN RUNE Y WITH CROSS |
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᚤ | y | yMD | 16A4 | MEDIEVAL RUNE DOTTED U |
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᚥ | w | wMD | 16A5 | MEDIEVAL RUNE W |
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᚦ | þ | thGE | 16A6 | GENERAL RUNE THORN (BRANCH CURVATURE NOT SPECIFIED) |
| ᚦ | þ | thGEcv | F41F | GENERAL RUNE THORN WITH CURVED BRANCHES |
| | þ | thGEst | F420 | GENERAL RUNE THORN WITH STRAIGHT BRANCHES |
| | þ | thGEfh | F421 | GENERAL RUNE THORN FLIPPED HORISONTALLY |
| | þ | thGElbo | F422 | GENERAL RUNE THORN WITH LARGE BOWL |
| | þ | thGEfbo | F423 | GENERAL RUNE THORN WITH FULL BOWL |
| | þ | thGEfhfbo | F424 | GENERAL RUNE THORN WITH FULL BOWL FLIPPED HORISONTALLY |
| | þ | thGEdblbo | F425 | GENERAL RUNE THORN WITH DOUBLE BOWL |
| | þ | thGEmirst | F426 | GENERAL RUNE MIRRORED THORN WITH STRAIGHT BRANCHES |
| | þ | thGEstbo | F427 | GENERAL RUNE THORN WITH STRAIGHT BOWL |
| | þ | thSL | F428 | STAVELESS RUNE THORN |
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᚧ | ð | dhMD | 16A7 | MEDIEVAL RUNE ETH |
| | ð | dhMDfbo | F429 | MEDIEVAL RUNE ETH WITH FULL BOWL |
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᚨ | a | aOR | 16A8 | OLDER RUNE A |
| | a | aORbrk | F42D | OLDER RUNE A BROKEN FORM |
| | a | acurly | F4BA | YOUNGER RUNE A CURLY FORM |
| The variant above is a peculiar form of the a rune, attested in a couple of Norwegian inscriptions, e.g. N 171 (dated to the 1190s). It looks a little like the s rune of the older futhark. | ||||
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᚩ | o | oAF | 16A9 | ANGLO-FRISIAN RUNE O |
| | o | oAFabr | F432 | ANGLO-FRISIAN RUNE O WITH ANGLED BRANCHES |
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᚪ | a | aAF | 16AA | ANGLO-FRISIAN RUNE A |
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᚫ | æ | aeAF | 16AB | ANGLO-FRISIAN RUNE AESC |
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᚬ | ã | anYGL | 16AC | YOUNGER LONG-BRANCH RUNE NASAL A |
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᚭ | ã | anYGS | 16AD | YOUNGER SHORT-TWIG RUNE NASAL A |
| | ã | anSL | F434 | STAVELESS RUNE NASAL A |
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᚮ | o | oYG | 16AE | YOUNGER RUNE O |
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᚯ | ø | oeMD | 16AF | MEDIEVAL RUNE O SLASH |
| | ø | oeMD3br | F436 | MEDIEVAL RUNE O SLASH WITH THREE BRANCHES |
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᚰ | ǫ | oeMDsht | 16B0 | MEDIEVAL RUNE O SLASH SHORTENED |
| | ǫ | oeMDsht1acr2lf | F438 | MEDIEVAL RUNE O SLASH SHORTENED WITH BRANCH ACROSS AND BRANCH TO THE RIGHT BELOW |
| | ǫ | oeMDsht1lf2acr | F439 | MEDIEVAL RUNE O SLASH SHORTENED WITH BRANCH TO THE LEFT AND BRANCH ACROSS BELOW |
| | ǫ | oeMDsht1rg2acr | F43A | MEDIEVAL RUNE O SLASH SHORTENED WITH BRANCH TO THE RIGHT AND BRANCH ACROSS BELOW |
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᚱ | r | rGE | 16B1 | GENERAL RUNE R (BRANCH CURVATURE NOT SPECIFIED) |
| ᚱ | r | rGEcv | F43D | GENERAL RUNE R WITH CURVED BRANCHES |
| | r | rGEst | F43E | GENERAL RUNE R WITH STRAIGHT BRANCHES |
| | r | rGEopen | F437 | GENERAL RUNE OPEN R |
| | r | rGEopencurly | F441 | GENERAL RUNE OPEN AND CURLY R |
| | r | rGEopendblcv | F443 | GENERAL RUNE OPEN R WITH CURVED BRANCHES |
| | r | rGEsmbo | F444 | GENERAL RUNE R WITH SMALL BOWL |
| | r | rGE2stor | F445 | GENERAL RUNE TWO-STOREYED R |
| | r | rGEfv | F446 | GENERAL RUNE R FLIPPED VERTICALLY |
| | r | rSL | F447 | STAVELESS RUNE R |
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᚲ | k | kOR | 16B2 | OLDER RUNE K |
| | k | kORyshp | F448 | OLDER RUNE Y-SHAPED K |
| | k | kORyshpvf | F449 | OLDER RUNE Y-SHAPED K VERTICALLY FLIPPED |
| | k | kORarrshp | F44A | OLDER RUNE ARROW-SHAPED K |
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᚳ | c | cAF | 16B3 | ANGLO-FRISIAN RUNE C |
| | c | cAFcv | F44D | ANGLO-FRISIAN RUNE C WITH CURVED BRANCH |
| | c | cAFfhcv | F44C | ANGLO-FRISIAN RUNE C WITH CURVED BRANCH FLIPPED HORISONTALLY |
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᚴ | k | kYG | 16B4 | YOUNGER RUNE K (BRANCH CURVATURE NOT SPECIFIED) |
| ᚴ | k | kYGcv | 16B4 | YOUNGER RUNE K WITH CURVED BRANCH |
| | k | kYGst | F44F | YOUNGER RUNE K WITH STRAIGHT BRANCH |
| | k | kYGfhst | F451 | YOUNGER RUNE K WITH STRAIGHT BRANCH FLIPPED HORISONTALLY |
| | k | kYGdblcv | F452 | YOUNGER RUNE K WITH DOUBLE CURVED BRANCHES |
| | k | kYGdblst | F453 | YOUNGER RUNE K WITH DOUBLE STRAIGHT BRANCHES |
| | k | kSLst | F454 | STAVELESS RUNE K STRAIGHT FORM |
| | k | kSLcv | F455 | STAVELESS RUNE K CURVED FORM |
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᚵ | g | gMD | 16B5 | MEDIEVAL RUNE G (BRANCH CURVATURE NOT SPECIFIED) |
| ᚵ | g | gMDcv | 16B5 | MEDIEVAL RUNE G WITH CURVED BRANCH |
| | g | gMDst | F457 | MEDIEVAL RUNE G WITH STRAIGHT BRANCH |
| | g | gMDfhst | F459 | MEDIEVAL RUNE G WITH STRAIGHT BRANCH FLIPPED HORISONTALLY |
| | g | gMDfhcv | F45A | MEDIEVAL RUNE G WITH CURVED BRANCH FLIPPED HORISONTALLY |
| | g | gMDcvst | F45B | MEDIEVAL RUNE G WITH CURVED BRANCH AND STROKE |
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᚶ | ŋ | ngMD | 16B6 | MEDIEVAL RUNE ENG (BRANCH CURVATURE NOT SPECIFIED) |
| ᚶ | ŋ | ngMDcv | F45E | MEDIEVAL RUNE ENG WITH CURVED BRANCH |
| | ŋ | ngMDst | F45E | MEDIEVAL RUNE ENG WITH STRAIGHT BRANCH |
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᚷ | g | gOR | 16B7 | OLDER RUNE G |
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᚸ | g | gAF | 16B8 | ANGLO-FRISIAN RUNE G |
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᚹ | w | wOR | 16B9 | OLDER RUNE W (BRANCH CURVATURE NOT SPECIFIED) |
| ᚹ | w | wORcv | F461 | OLDER RUNE W WITH CURVED BRANCHES |
| | w | wORst | F462 | OLDER RUNE W WITH STRAIGHT BRANCHES |
| | w | wORmirst | F463 | OLDER RUNE MIRRORED W WITH STRAIGHT BRANCHES |
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᚺ | h | hOR | 16BA | OLDER RUNE H |
| | h | hORfh | F465 | OLDER RUNE H FLIPPED HORISONTALLY |
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᚻ | h | hAF | 16BB | ANGLO-FRISIAN RUNE H |
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᚼ | x | xMDhtyp | 16BC | MEDIEVAL RUNE H-TYPE X |
| | x | xMDhtypstk | F515 | MEDIEVAL RUNE H-TYPE X WITH TERMINAL STROKES |
| | x | xMDhtypdot | F516 | MEDIEVAL RUNE H-TYPE X WITH TERMINAL DOTS |
| | x | xMDaddstk | F468 | MEDIEVAL RUNE H-TYPE X WITH ADDITIONAL BRANCH ACROSS |
| | x | xMDplus | F469 | MEDIEVAL RUNE PLUS-SHAPED X |
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᚽ | h | hYGS | 16BD | YOUNGER SHORT-TWIG RUNE H |
| | h | hYGSstk | F46C | YOUNGER SHORT-TWIG RUNE H WITH STROKE |
| | h | hSL | F46D | STAVELESS RUNE H |
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᚾ | n | nOR | 16BE | OLDER RUNE N |
| | n | nORfh | F470 | OLDER RUNE N FLIPPED HORISONTALLY |
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᚿ | n | nYG | 16BF | YOUNGER RUNE N |
| | n | nYGdot | F473 | YOUNGER RUNE N WITH DOT |
| | n | nYGtop | F474 | YOUNGER RUNE N WITH BRANCH FROM TOP |
| | n | nSL | F475 | STAVELESS RUNE N |
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᛀ | n | nMDdot | 16C0 | MEDIEVAL RUNE DOTTED N |
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᛁ | i | iGE | 16C1 | GENERAL RUNE I |
| | i | iSL | F479 | STAVELESS RUNE I |
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᛂ | e | eMD | 16C2 | MEDIEVAL RUNE E |
| | e | eMDstk | F47B | MEDIEVAL RUNE E WITH STROKE |
| | e | eMDcrc | F47C | MEDIEVAL RUNE E WITH CIRCLE |
| | e | eMDlcrc | F47D | MEDIEVAL RUNE E WITH LARGE CIRCLE |
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᛃ | j | jOR | 16C3 | OLDER RUNE J |
| | j | jORfh | F480 | OLDER RUNE J FLIPPED HORISONTALLY |
| | j | jORcvvert | F481 | OLDER RUNE CURVED J VERTICAL |
| | j | jORcvobl | F482 | OLDER RUNE CURVED J OBLIQUE |
| | j | jORdblcvhor | F483 | OLDER RUNE DOUBLE CURVED HORISONTAL J |
| | j | jORdblcvvert | F484 | OLDER RUNE DOUBLE CURVED VERTICAL J |
| | j | jORdblwedclos | F485 | OLDER RUNE DOUBLE CLOSED WEDGE J |
| | j | jORdblwedopen | F486 | OLDER RUNE DOUBLE OPEN WEDGE J |
| | j | jORbrk | F487 | OLDER RUNE BROKEN J |
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᛄ | j | jAF | 16C4 | ANGLO-FRISIAN RUNE J WITH RHOMBUS |
| | j | jAFcirc | F489 | ANGLO-FRISIAN RUNE J WITH CIRCLE |
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᛅ | æ | aeMD | 16C5 | MEDIEVAL RUNE AE |
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᛆ | a | aYG | 16C6 | YOUNGER RUNE A |
| | a | aYGlongbr | F48B | YOUNGER RUNE A WITH LONG LEFT BRANCH |
| Note: The variant above is attested in Codex Runicus (AM 28 8vo). | ||||
| | a | aYGruw | F48C | YOUNGER RUNE A WITH SHORT RIGHT TWIG |
| | a | aYGluw | F48D | YOUNGER RUNE A WITH SHORT LEFT TWIG |
| | a | aYGdot | F48E | YOUNGER RUNE A WITH DOT |
| | a | aSL | F48F | STAVELESS RUNE A |
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᛇ | ë | iwazOR | 16C7 | OLDER RUNE IWAZ |
| | ë | iwazORfh | F492 | OLDER RUNE IWAZ FLIPPED HORISONTALLY |
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᛈ | p | pOR | 16C8 | OLDER RUNE P |
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᛉ | ʀ | zOR | 16C9 | OLDER RUNE Z (BRANCH CURVATURE NOT SPECIFIED) |
| ᛉ | ʀ | zORcv | 16C9 | OLDER RUNE Z WITH CURVED BRANCHES |
| | ʀ | zORst | F493 | OLDER RUNE Z WITH STRAIGHT BRANCHES |
| | ʀ | zORfv | F495 | OLDER RUNE Z FLIPPED VERTICALLY |
| | ʀ | zORfvst | F496 | OLDER RUNE Z WITH STRAIGHT BRANCHES FLIPPED VERTICALLY |
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᛊ | s | sOR | 16CA | OLDER RUNE S |
| | s | sOR3brk | F498 | OLDER RUNE S WITH THREE BREAKS |
| | s | sOR4brk | F499 | OLDER RUNE S WITH FOUR BREAKS |
| | s | sOR4cvbrk | F49A | OLDER RUNE S WITH FOUR CURVED BREAKS |
| | s | sORbrk | F49B | OLDER RUNE BROKEN S |
| | s | sORfhbrk | F49C | OLDER RUNE BROKEN S FLIPPED HORISONTALLY |
| | s | sORbshp | F49D | OLDER RUNE B-SHAPED S |
| | s | sORfiveshp | F49E | OLDER RUNE FIVE-SHAPED S |
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᛋ | z | zMD | 16CB | MEDIEVAL RUNE Z |
| | z | zMDfh | F4A3 | MEDIEVAL RUNE Z FLIPPED HORISONTALLY |
| | z | zMDhshp | F4A4 | MEDIEVAL RUNE H-SHAPED Z |
| | z | zMDhshpfh | F4B3 | MEDIEVAL RUNE H-SHAPED Z FLIPPED HORISONTALLY |
| | z | zMDdblmidstk | F4A5 | MEDIEVAL RUNE Z WITH DOUBLE MIDDLE STROKE |
| | z | zMDtalbrk | F4A6 | MEDIEVAL RUNE Z WITH TALL BREAK |
| | z | zMDtalbrkfh | F4A7 | MEDIEVAL RUNE Z WITH TALL BREAK FLIPPED HORISONTALLY |
| | z | zMD4sh | F4AF | MEDIEVAL RUNE FOUR-SHAPED Z |
| | z | zMD4shfh | F4AE | MEDIEVAL RUNE FOUR-SHAPED Z FLIPPED HORISONTALLY |
| Note: The two runes above are recorded as variants of s by Wimmer and Jacobsen (1914: 252), alongside ᛋ and . | ||||
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᛌ | s | sYGS | 16CC | YOUNGER RUNE SHORT-TWIG S |
| ᛍ | s | sYGSdot | 16CD | YOUNGER RUNE SHORT-TWIG S WITH DOT |
| | s | sYGScrc | F4A9 | YOUNGER RUNE SHORT-TWIG S WITH CIRCLE |
| | s | sYGtaldot | F4AA | YOUNGER RUNE TALL S WITH DOT |
| | s | sYGtalcrc | F4AB | YOUNGER RUNE TALL S WITH CIRCLE |
| | s | sSL | F4AC | STAVELESS RUNE S |
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᛍ | s | sYGSdot | 16CD | YOUNGER RUNE SHORT-TWIG S WITH DOT |
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᛎ | z | zMDsht | 16CE | MEDIEVAL SHORT RUNE Z |
| | z | zMDtal | F4B0 | MEDIEVAL TALL RUNE Z |
| | z | zMDruw | F4B1 | MEDIEVAL TALL RUNE Z WITH SINGLE RIGHT BRANCH |
| | z | zMDshtruw | F4B2 | MEDIEVAL SHORT RUNE Z WITH SINGLE RIGHT BRANCH |
| Note: The single-branch variant above is the common form of the z rune in Codex Runicus (AM 28 8vo). | ||||
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᛏ | t | tOR | 16CF | OLDER RUNE T |
| | t | tORdot | F4B6 | OLDER RUNE T WITH DOT |
| | t | tORdgstktop | F4B7 | OLDER RUNE T WITH DIAGONAL STROKE ACROSS TOP |
| | t | tORdblmidbr | F4B8 | OLDER RUNE T WITH DOUBLE MIDDLE BRANCHES |
| | t | tSL | F4B9 | STAVELESS RUNE T |
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᛐ | t | tYG | 16D0 | YOUNGER RUNE T |
| | t | tYGrang | F4BC | YOUNGER RUNE T WITH RIGHT-ANGLED BRANCH |
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᛑ | d | dMD | 16D1 | MEDIEVAL RUNE D WITH DOT ON STAVE |
| | d | dMDstk | F4C0 | MEDIEVAL RUNE D WITH STROKE |
| | d | dMDstkcv | F4BF | MEDIEVAL RUNE D WITH STROKE AND CURVED BRANCH |
| | d | dMDcrc | F4C1 | MEDIEVAL RUNE D WITH CIRCLE |
| | d | dMDdot | F4C2 | MEDIEVAL RUNE D WITH DOT |
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᛒ | b | bGE | 16D2 | GENERAL RUNE B (BRANCH CURVATURE NOT SPECIFIED) |
| ᛒ | b | bGEcv | F4C5 | GENERAL RUNE B WITH CURVED BRANCHES |
| | b | bGEst | F4C6 | GENERAL RUNE B WITH STRAIGHT BRANCHES |
| | b | bGEupbo | F4C7 | GENERAL RUNE B WITH UPPER BOWL |
| | b | bGElobo | F4C8 | GENERAL RUNE B WITH LOWER BOWL |
| | b | bGEuplobo | F4C9 | GENERAL RUNE B WITH UPPER AND LOWER BOWL |
| | b | bGEfhuplobo | F4CA | GENERAL RUNE B WITH UPPER AND LOWER BOWL FLIPPED HORISONTALLY |
| | b | bSL | F4CB | STAVELESS RUNE B |
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᛓ | b | bYGS | 16D3 | YOUNGER RUNE SHORT-TWIG B |
| | b | bYGSbrlf | F4D0 | YOUNGER RUNE SHORT-TWIG B WITH BRANCHES TO THE LEFT |
| | b | bYGSbracr | F4D1 | YOUNGER RUNE SHORT-TWIG B WITH BRANCHES ACROSS |
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᛔ | p | pMD | 16D4 | MEDIEVAL RUNE P (BRANCH CURVATURE NOT SPECIFIED) |
| ᛔ | p | pMDcv | 16D4 | MEDIEVAL RUNE P WITH CURVED BRANCHES |
| | p | pMDst | F4D4 | MEDIEVAL RUNE P WITH STRAIGHT BRANCHES |
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᛕ | p | pMDopen | 16D5 | MEDIEVAL RUNE OPEN P (BRANCH CURVATURE NOT SPECIFIED) |
| | p | pMDstopen | F4D7 | MEDIEVAL RUNE OPEN P WITH STRAIGHT BRANCHES |
| | p | pMDcvopen | F4D8 | MEDIEVAL RUNE OPEN P WITH CURVED BRANCHES |
| | p | pMDcvopencurl | F4D9 | MEDIEVAL RUNE OPEN P WITH CURVED BRANCH AND CURLED BRANCH |
| | p | pMDfhopen | F4DA | MEDIEVAL RUNE OPEN P FLIPPED HORISONTALLY |
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᛖ | e | eOR | 16D6 | OLDER RUNE E |
| | e | eORflat | F4DD | OLDER RUNE E WITH FLAT TOP |
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᛗ | m | mOR | 16D7 | OLDER RUNE M |
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᛘ | m | mYGL | 16D8 | YOUNGER RUNE LONG-BRANCH M (BRANCH CURVATURE NOT SPECIFIED) |
| ᛘ | m | mYGLcv | 16D8 | YOUNGER RUNE LONG-BRANCH M WITH CURVED BRANCHES |
| | m | mYGLst | F4DF | YOUNGER RUNE LONG-BRANCH M WITH STRAIGHT BRANCHES |
| | m | mYGLcrc | F4E1 | YOUNGER RUNE LONG-BRANCH M WITH CIRCULAR BRANCHES |
| | m | mYGLdbldot | F4E5 | YOUNGER RUNE LONG-BRANCH M WITH DOUBLE DOTS |
| Note: The rune above is attested in Wimmer and Jacobsen (1914: 246). | ||||
| | m | mYGLtalbr | F4E2 | YOUNGER RUNE LONG-BRANCH M WITH TALL CURVED BRANCHES |
| | m | mYGLhfhtbr | F4DE | YOUNGER RUNE LONG-BRANCH M WITH HALF HEIGHT CURVED BRANCHES |
| | m | mYGLsqbr | F4E3 | YOUNGER RUNE LONG-BRANCH M WITH SQUARE BRANCHES |
| | m | mSL | F4E4 | STAVELESS RUNE M |
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᛙ | m | mYGS | 16D9 | YOUNGER RUNE SHORT-TWIG M |
| | m | mYGSstk | F4E6 | YOUNGER RUNE SHORT-TWIG M WITH HIGH STROKE |
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᛚ | l | lGE | 16DA | GENERAL RUNE L |
| | l | lGEdgstktop | F4E8 | GENERAL RUNE L WITH DIAGONAL STROKE ACROSS TOP |
| | l | lGEdot | F4E9 | GENERAL RUNE L WITH DOT |
| | l | lGErang | F4EA | GENERAL RUNE L WITH RIGHT-ANGLED BRANCH |
| | l | lSL | F4EB | STAVELESS RUNE L |
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᛛ | l? | lMDdot | 16DB | MEDIEVAL RUNE L WITH DOT |
| | l? | lMDstk | F4C3 | MEDIEVAL RUNE L WITH STROKE |
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᛜ | ŋ | ngOR | 16DC | OLDER RUNE NG |
| | ŋ | ngORsqr | F4F0 | OLDER RUNE SQUARE NG |
| | ŋ | ngORcrc | F4F1 | OLDER RUNE CIRCULAR NG |
| | ŋ | ngORstv | F4F2 | OLDER RUNE NG ON STAVE |
| | ŋ | ngORcrcstv | F4F3 | OLDER RUNE CIRCULAR NG ON STAVE |
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᛝ | ŋ | ngAF | 16DD | ANGLO-FRISIAN RUNE NG |
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᛞ | d | dOR | 16DE | OLDER RUNE D |
| | d | dORmid | F4F5 | OLDER RUNE D WITH MIDDLE BRANCHES |
| | d | dORcv | F4F6 | OLDER RUNE D WITH CURVED BRANCHES |
| | d | dORsing | F4F4 | OLDER RUNE D WITH SINGLE BRANCHES |
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᛟ | o | oOR | 16DF | OLDER RUNE O |
| | o | oORcrc | F500 | OLDER RUNE CIRCULAR O |
| | o | oORsmcrc | F501 | OLDER RUNE SMALL CIRCULAR O |
| | o | oORfish | F502 | OLDER RUNE FISH-SHAPED O |
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᛠ | ea | eaAF | 16E0 | ANGLO-FRISIAN RUNE EAR |
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᛡ | j | ioAF | 16E1 | ANGLO-FRISIAN RUNE IOR |
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᛢ | q | qAF | 16E2 | ANGLO-FRISIAN RUNE CWEORTH |
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᛣ | k | kAF | 16E3 | ANGLO-FRISIAN RUNE CALC (BRANCH CURVATURE NOT SPECIFIED) |
| | k | kAFcv | F507 | ANGLO-FRISIAN RUNE CALC WITH CURVED BRANCHES |
| | k | kAFst | F504 | ANGLO-FRISIAN RUNE CALC WITH STRAIGHT BRANCHES |
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᛤ | k’ | kjAF | 16E4 | ANGLO-FRISIAN RUNE CEALC |
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᛥ | st | stAF | 16E5 | ANGLO-FRISIAN RUNE STAN |
| | st | stAFopen | F506 | ANGLO-FRISIAN OPEN RUNE STAN |
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᛦ | y | yYG | 16E6 | YOUNGER RUNE Y (BRANCH CURVATURE NOT SPECIFIED) |
| ᛦ | y | yYGcv | F507 | YOUNGER RUNE Y WITH CURVED BRANCHES |
| | y | yYGst | F504 | YOUNGER RUNE Y WITH STRAIGHT BRANCHES |
| | y | yYGstdblbr | F509 | YOUNGER RUNE Y WITH DOUBLE STRAIGHT BRANCHES |
| | y | yYGsttribr | F508
| YOUNGER RUNE Y WITH TRIPLE STRAIGHT BRANCHES |
| | y | yYGstdblbrtb | F50A | YOUNGER RUNE Y WITH STRAIGHT BRANCHES ON TOP AND BOTTOM |
| | y | yYGtalbr | F50B | YOUNGER RUNE Y WITH TALL BRANCHES |
| | y | ySL | F50C | STAVELESS RUNE Y |
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᛧ | ʀ | RYGS | 16E7 | YOUNGER RUNE SHORT-TWIG R |
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᛨ | y | yMDisl | 16E8 | MEDIEVAL RUNE ICELANDIC Y |
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᛩ | q | qMD | 16E9 | MEDIEVAL RUNE Q (BRANCH CURVATURE NOT SPECIFIED) |
| ᛩ | q | qMDcv | F511 | MEDIEVAL RUNE Q WITH CURVED BRANCHES |
| | q | qMDst | F510 | MEDIEVAL RUNE Q WITH STRAIGHT BRANCHES |
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᛪ | x | xMDstyp | 16EA | MEDIEVAL RUNE S-TYPE X WITH STROKES |
| | x | xMDstypdg | F513 | MEDIEVAL RUNE S-TYPE X WITH DIAGONAL STROKES |
| | x | xMDcros | F514 | MEDIEVAL RUNE CROSS-SHAPED X |
Finally, this chapter offers a list of punctuation marks. Some of them have been used throughout the whole period of runic writing.
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᛫ | : | middotPM | 16EB | PUNCTUATION MARK MIDDOT |
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᛬ | : | twodotPM | 16EC | PUNCTUATION MARK TWO VERTICAL DOTS |
| | : | semidotPM | F520 | PUNCTUATION MARK SEMICOLON |
| | : | threedotPM | F521 | PUNCTUATION MARK THREE VERTICAL DOTS |
| | : | fourdotPM | F522 | PUNCTUATION MARK FOUR VERTICAL DOTS |
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᛭ | ⁘ | crosPM | 16ED | PUNCTUATION MARK CROSS |
| | ⁘ | cros5dotsPM | F528 | PUNCTUATION MARK CROSS FIVE DOTS |
| | ⁘ | cros4dotsPM | F529 | PUNCTUATION MARK CROSS FOUR DOTS |
It is also possible to use existing punctuation marks in the Unicode Standard. This table has a list of candidates:
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᛬ | : | runmultpunct | 16EC | RUNIC MULTIPLE PUNCTUATION |
| ᛫ | : | runsignpunct | 16EB | RUNIC SINGLE PUNCTUATION |
| ⁌ | : | blaleftbul | 204C | BLACK LEFTWARDS BULLET |
| ⁍ | : | blarightbul | 204D | BLACK RIGHTWARDS BULLET |
| ⁖ | : | threedotpunct | 2056 | THREE DOT PUNCTUATION |
| ⁙ | : | fivedotpunct | 2059 | FIVE DOT PUNCTUATION |
| ⁚ | : | twodotpunct | 205A | TWO DOT PUNCTUATION |
| ⁛ | : | fourdotsm | 205B | FOUR DOT MARK |
| ⁝ | : | tricol | 205D | TRICOLON |
| ⁞ | : | verfourdots | 205E | VERTICAL FOUR DOTS |
18.6.3 Specific runic rows
Introductions in runology tend to list several variants of the younger runic alphabet. Among these are the long-branch runes, the short-twig runes and what has been termed the Norwegian “mixed” futhark (see e.g. Barnes 2012: 61–62). Since this chapter primarily has been written from a Norwegian point of view, the latter row will be shown in the table below.
| Glyph | Translit. | Encoding | Code point | Menota descriptive name |
|---|---|---|---|---|
| ᚠ | f | fGE | 16A0 | GENERAL RUNE F |
| ᚢ | u | uGE | 16A2 | GENERAL RUNE U |
| ᚦ | þ | thGE | 16A6 | GENERAL RUNE THORN |
| ᚮ | o | oYG | 16AE | YOUNGER RUNE O |
| ᚱ | r | rGE | 16B1 | GENERAL RUNE R |
| ᚴ | k | kYG | 16B4 | YOUNGER RUNE K |
| ᚼ | h | hYGL | 16BC | YOUNGER LONG-BRANCH RUNE H |
| ᚿ | n | nYGS | 16BF | YOUNGER SHORT-TWIG RUNE N |
| ᛁ | i | iGE | 16C1 | GENERAL RUNE I |
| ᛆ | a | aYG | 16C6 | YOUNGER RUNE A |
| ᛋ | s | sYGL | 16CB | YOUNGER RUNE LONG-BRANCH S |
| ᛌ | s | sYGS | 16CC | YOUNGER RUNE SHORT-TWIG S |
| ᛐ | t | tYG | 16D0 | YOUNGER RUNE T |
| ᛒ | b | bGE | 16D2 | GENERAL RUNE B |
| ᛘ | m | mYGL | 16D8 | YOUNGER RUNE LONG-BRANCH M |
| ᛚ | l | lGE | 16DA | GENERAL RUNE L |
| ᛦ | y | yYG | 16E6 | YOUNGER RUNE Y |
The only rune for which two variants have been recorded is the s rune, which can have the long-branch shape ᛋ or the short-twig shape ᛌ. Also note that the rune ᛦ is used for the vowel y in this row. It is problematic, perhaps, that the Unicode runic chart has the same codepoint, 16E6, for the rune which in the early period was used for the consonant ʀ (an r sound which merged with the r sound still used today) and eventually for the vowel y.
18.7 Example file
We offer one file for download:
Please note that some browsers may try and interpret and open these sample files. In order to download the file to your disk, use alt-click (Mac) or right-click (Windows) on your browser, unless your browser has other preferences.
Almost all texts in the Menota archive can be downloaded as XML files. This means that almost any file in the archive can be inspected, and, if convenient, used as a template.
18.8 Bibliographical references
This is a preliminary list of bibliographical references in the chapter.
Barnes, Michael P. 2012. Runes: A Handbook. Woodbridge: The Boydell Press. 240 pp.
Düwel, Klaus. 2001. Runenkunde. 3rd edition. Stuttgart: Metzler. 270 pp. [There is a 4th edition of this book.]
MacLeod, Mindy. 2002. Bind-runes: An Investigation of Ligatures in Runic Epigraphy. Runrön, vol. 15. Uppsala: Institutionen för nordiska språk. 348 pp.
NIyR = Norges innskrifter med de yngre runer. Eds. Magnus Olsen, Aslak Liestøl et al. Vol. 1 (1941), vol. 2 (1951), vol. 3 (1954), vol. 4 (1957), vol. 5 (1960), vol. 6:1 (1980), vol. 6:2 (1990), vol. 7 (in preparation). Oslo: Kjeldeskriftfondet.
SamNord = Samnordisk runetekstdatabase. Developed at the University of Uppsala since the 1980’s and in 2020 published with a search interface on the website of the Swedish National Heritage Board (Riksantikvarieämbetet), https://app.raa.se/open/runor/search.
Seim, Karin Fjellhammer. 2013. “Runologi”. Ch. 3 in Handbok i norrøn filologi, edited by Odd Einar Haugen, 128–193. Bergen: Fagbokforlaget. 66 pp.
Spurkland, Terje. 2001. I begynnelsen var fuþark: Norske runer og runeinnskrifter. Oslo: Cappelen. 220 pp.
Wimmer, Ludvig, and Lis Jacobsen. 1914. De danske runemindesmærker. Vol. 4. København: Gyldendal. – Ch. 5, Runestenene på Bornholm, pp. 181–328.